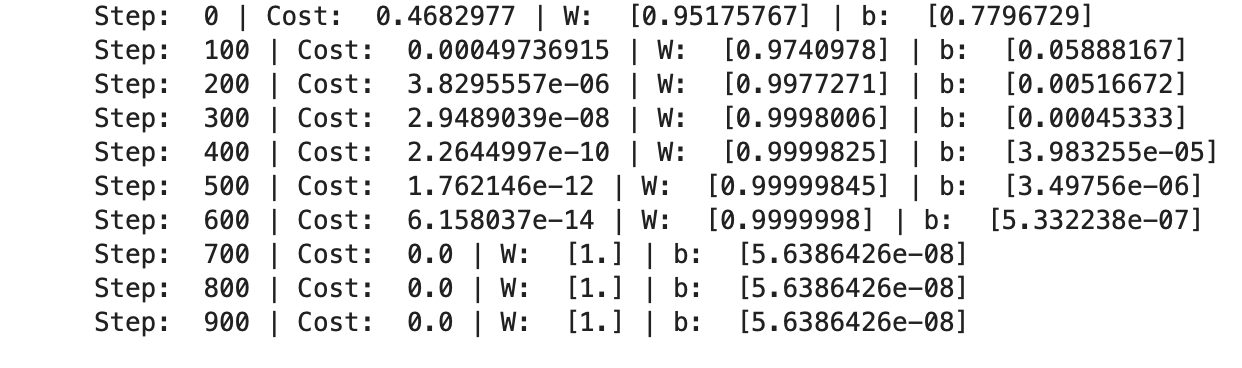
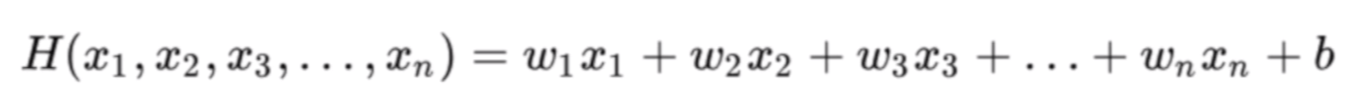의미 : Regression toward the mean → 데이터들은 전체의 평균으로 되돌아가려는 특징이 있다는 의미
2. Linear Regression
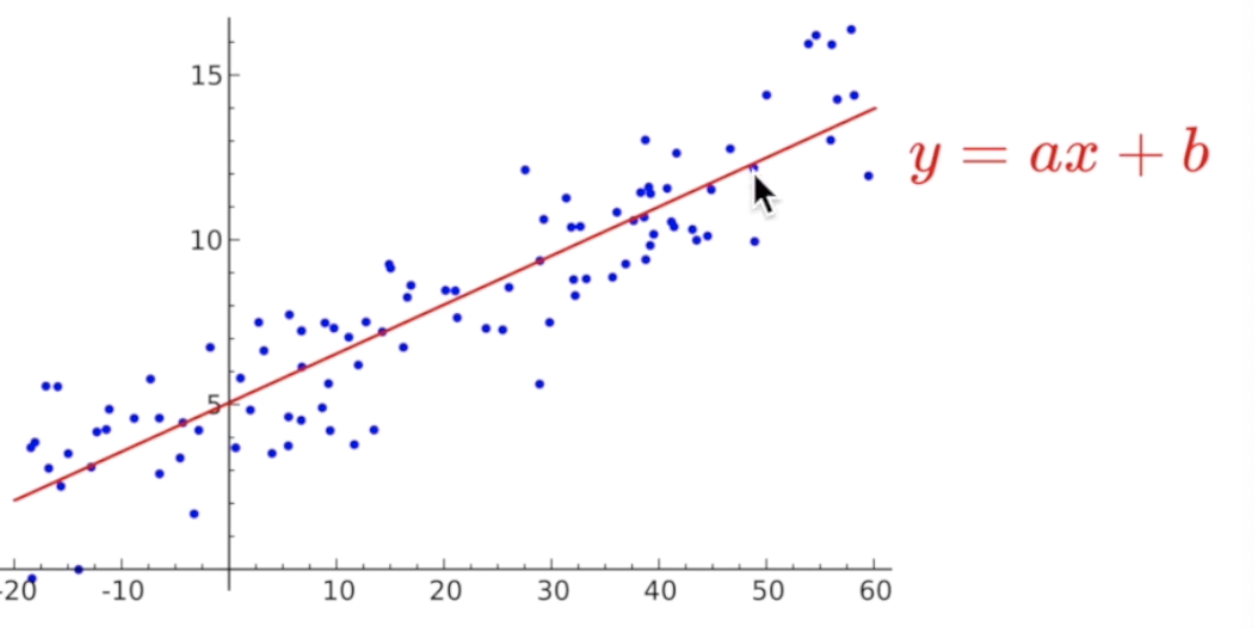
데이터(아래의 파란색 점)를 가장 잘 대변하는 직선의 방정식을 찾는 것(기울기와 절편을 찾는 것)
3. Hypothesis
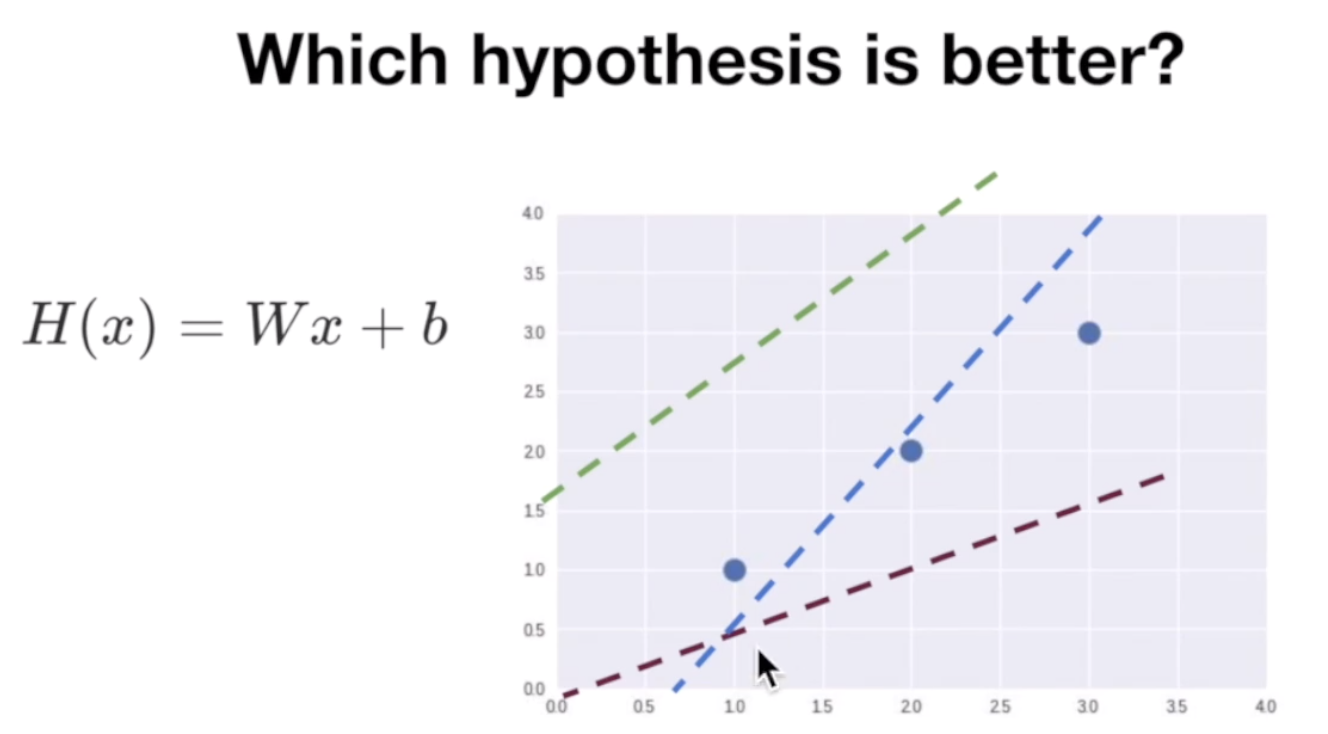
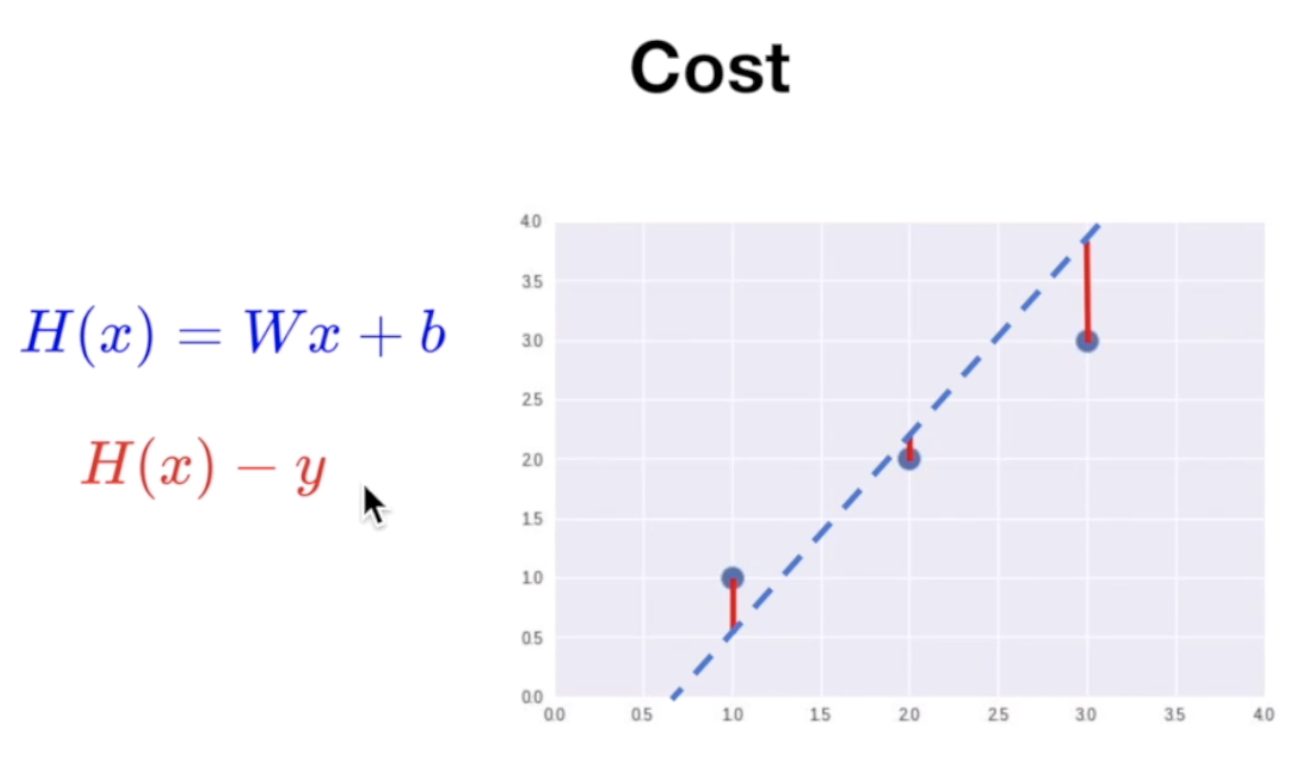
데이터를 대변하는 것으로 생각되는 직선의 식(가설)을 H(x) = Wx + b 라고 한다. 이 때의 W를 Weight, b를 bias라고 한다.
위 그래프의 파란 세점을 나타내는 세 개의 선이 있다고 하자. 이 경우에는 파란색 점선이 가장 이 점들을 잘 나타내는 것으로 보인다. 이 때의 W와 b를 어떻게 정의할 수 있을까?
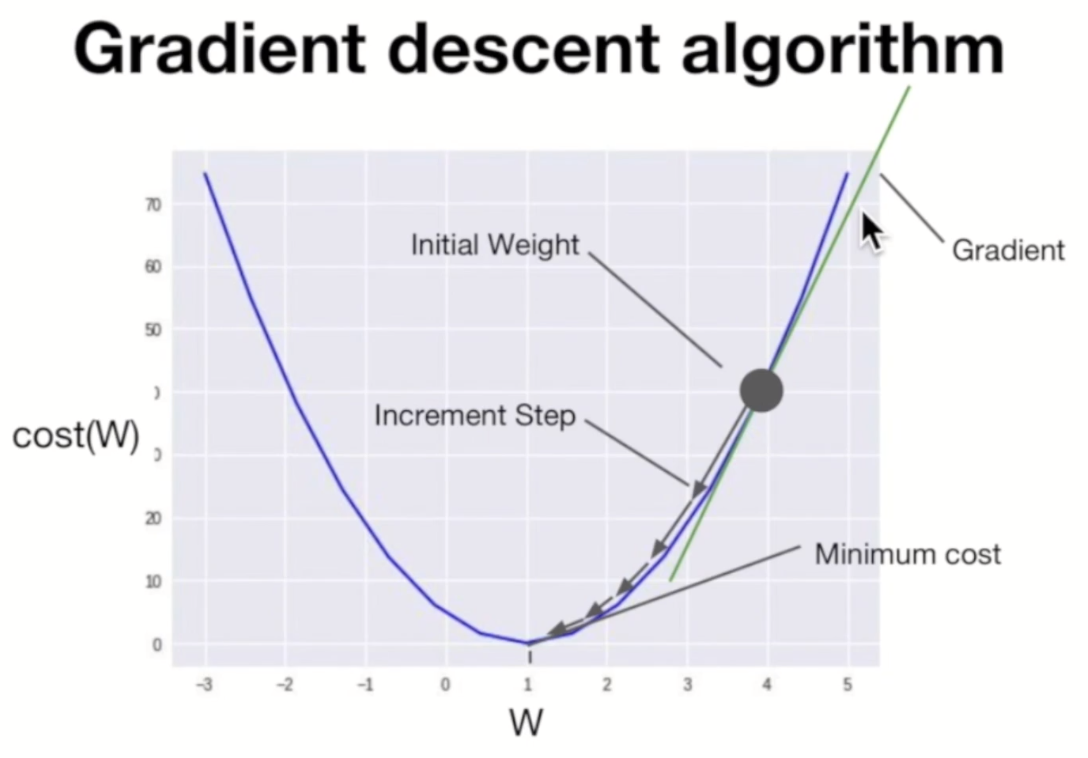
4. Cost
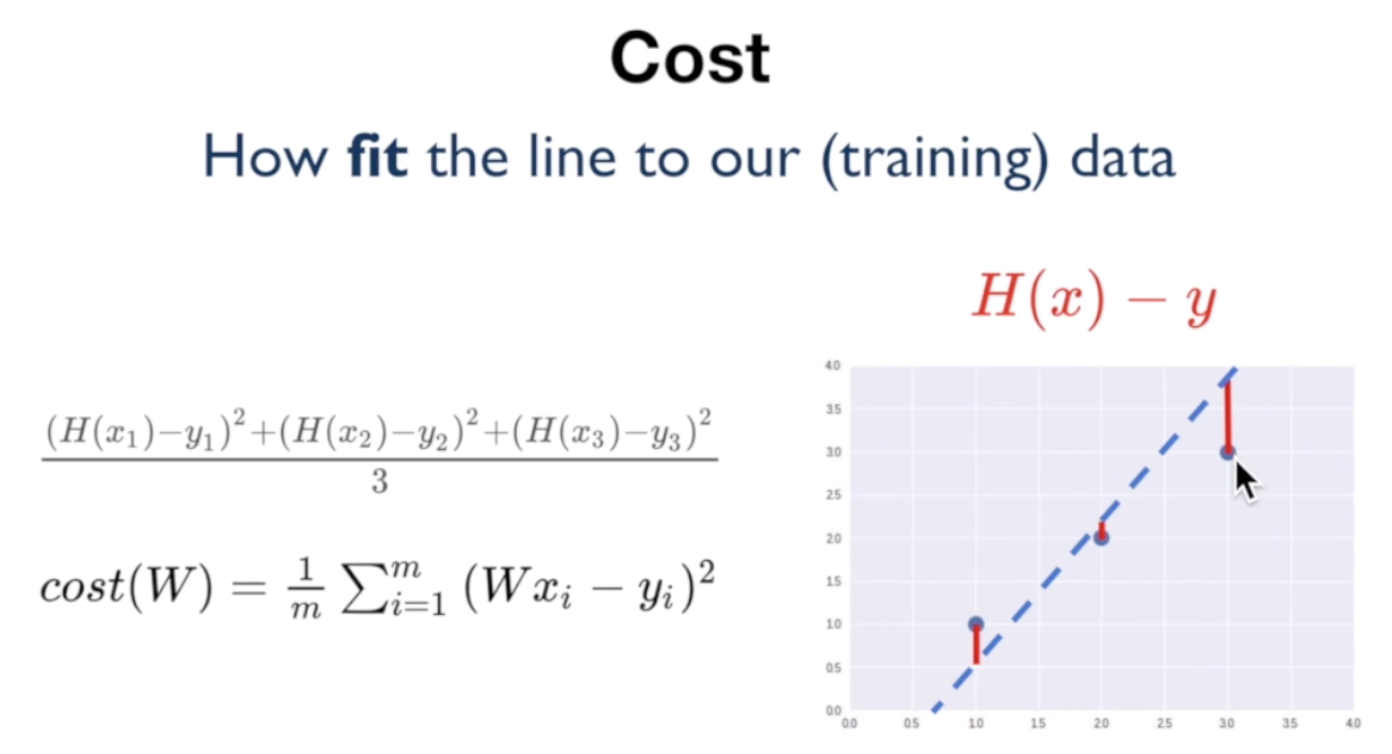
H(x) = Wx + b의 W와 b값을 찾기 위해 Cost라는 개념을 도입하게 된다. 위의 그래프에서 가설의 그래프가 실제 데이터(점)과의 거리, H(x)-y를 Error 혹은 Cost라고 한다. 이 Cost가 작을수록 점선(가설)이 데이터를 잘 대변한다고 볼 수 있다.
그런데 이 때, 단순히 합을 최소화하고자 할 때, 데이터에 따라 Cost 값이 양수일수도 음수일수도 있다. 실제 데이터와 차이가 많이 나더라도, 양수와 음수 값이 서로 상쇄해서 Cost가 적은 것처럼 보일 수 있다. 이 점을 보완하기 위해서 각 Error의 제곱을 합산해서 이 값의 최소값을 구하는 방식이 많이 사용된다.
가설의 비용함수(Cost function)을 아래와 같이 나타낼 수 있다.
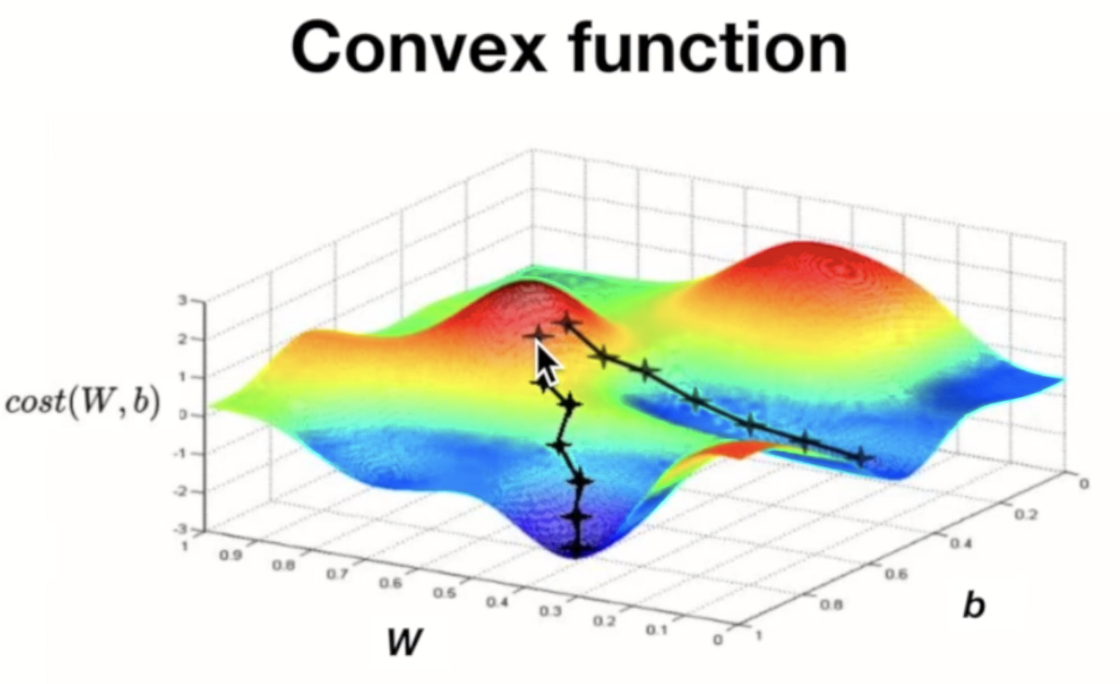
이 때 W와 b의 함수인 비용함수를 최소화하는 것이 선형회귀에서의 우리의 목표라 할 수 있다.
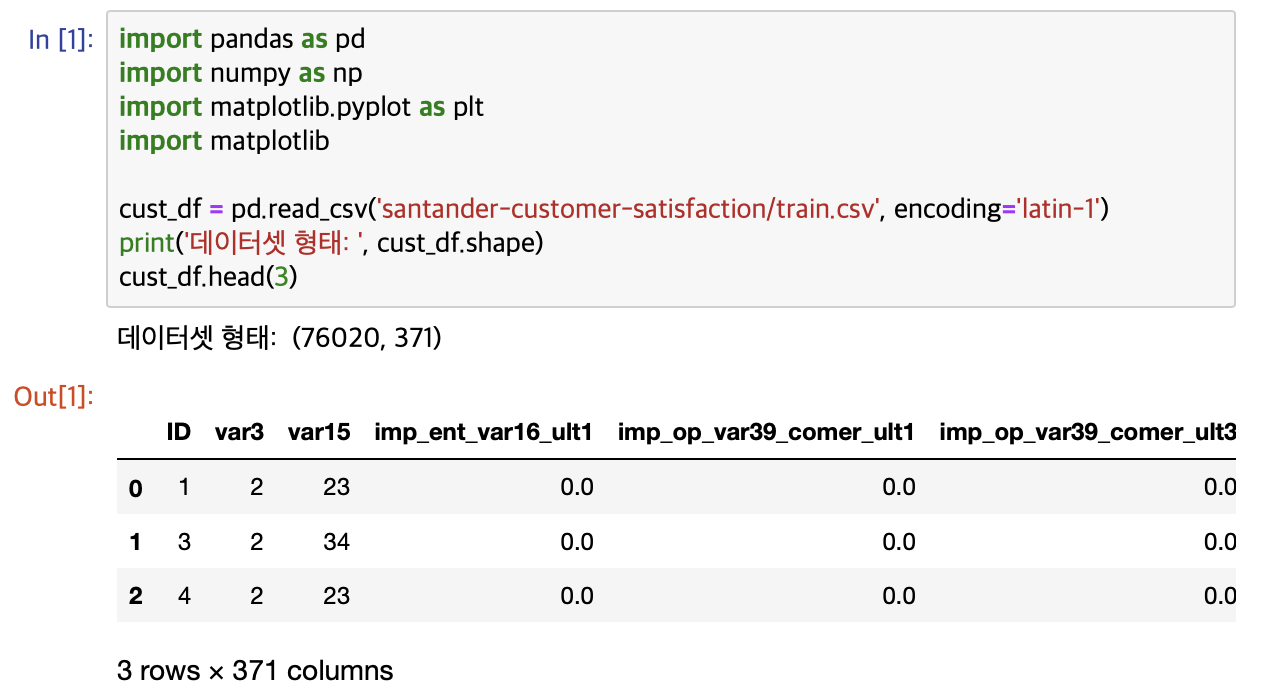
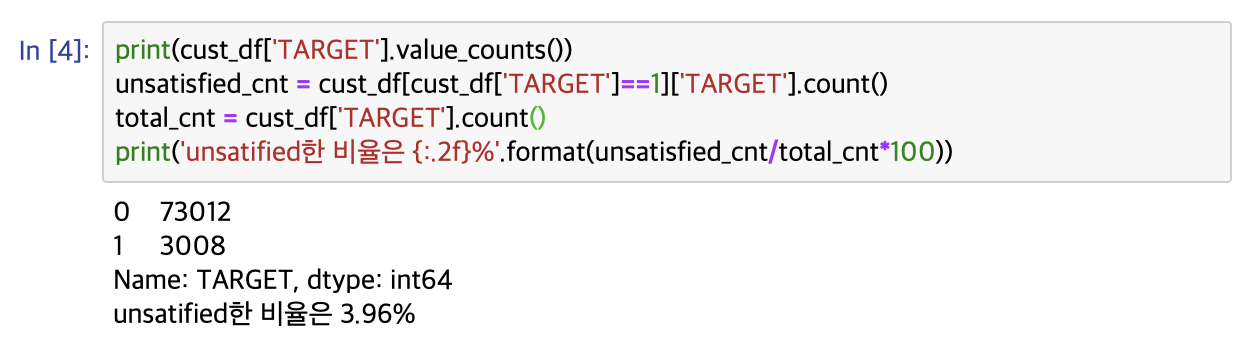
370개의 피처로 이루어진 데이터 세트 기반에서 고객만족 여부를 예측하는 것 피처이름은 모두 익명화되어 있어 어떤 속성인지는 알 수 없습니다.
클래스 레이블명은 TARGET이며 1이면 불만, 0이면 만족한 고객입니다.
모델의 성능평가는 ROC-AUC로 평가합니다. 대부분이 만족이고, 불만족인 데이터는 일부이기 때문에 단순 정확도 수치보다 ROU-AUC가 더 적합합니다.
데이터 전처리
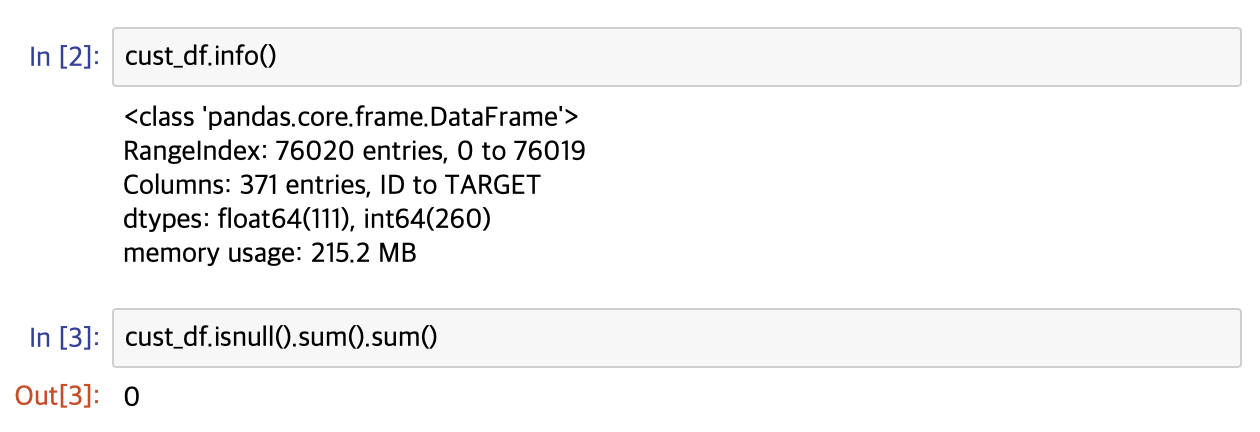
클래스 값 컬럼을 포함하면 총 371개의 피처가 존재합니다. 피처들의 타입과 Null값을 더 살펴보겠습니다.
111개의 피처가 float형, 260개의 피처가 int형이며 NULL 값은 존재하지 않습니다. 다음으로 레이블인 TARGET의 분포를 살펴보겠습니다.
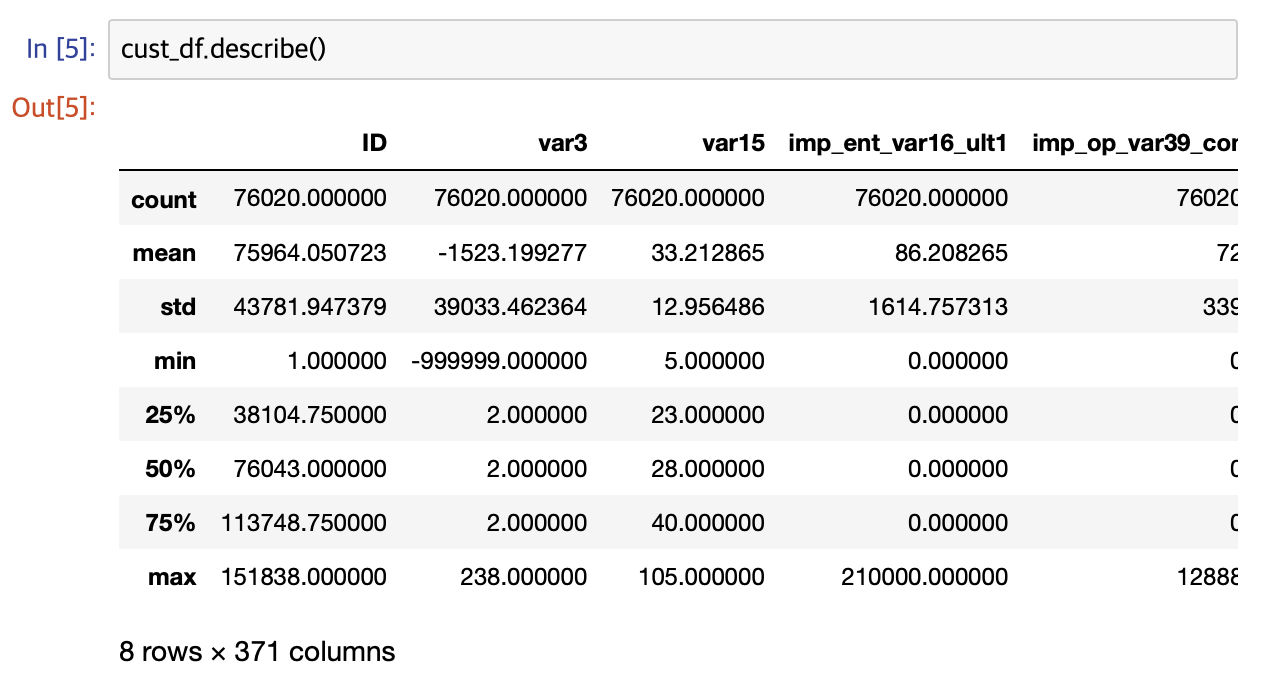
데이터프레임의 describe() 메소드를 사용해 각 피처의 값 분포를 간단히 확인해보겠습니다.
var3의 경우 최소값이 -999999로 나왔는데 1, 2, 3분위 수나 최댓값으로 미루어 보았을 때 결측치로 보입니다.
-999999의 값은 116개로 전체 데이터에 대해 비중이 적으므로 가장 값이 많은 2로 대체하겠습니다. 그리고 ID는 단순 식별자이므로 피처에서 드롭하겠습니다. 그 후에 피처들과 레이블 데이터를 분리해서 별도로 저장하겠습니다.
이후 성능평가를 위해서 현재 데이터 세트를 학습과 테스트 데이터 세트로 분리하겠습니다. 비대칭 데이터 세트이기 때문에 레이블의 분포가 원 데이터와 유사하게 추출되었는지 확인해보겠습니다.
데이터 세트 분할 결과 원 데이터셋과 유사하게 unsatisfied의 비율이 4%에 근접하는 수준이 되었습니다.
XGBoost 모델 학습과 하이퍼 파라미터 튜닝
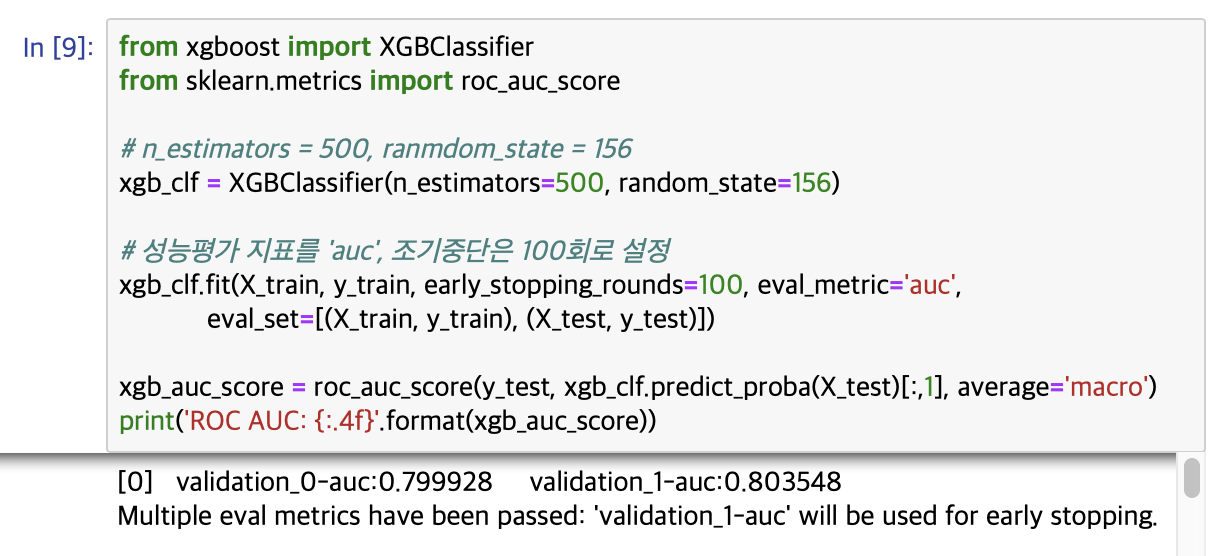
XGBoost로 기본 세팅을 아래와 설정하고, 예측결과를 ROC-AUC로 평가해보겠습니다.
n_estimators = 500
early_stopping_rounds = 100
eval_metric = 'auc'
평가 데이터세트는 앞에서 분리한 테스트 데이터 세트를 이용하겠습니다. 테스트 데이터 세트를 XGBoost의 평가 데이터 세트로 사용하면 과적합이 될 우려가 있지만, 일단 진행하겠습니다.
eval_set = [(X_train, y_train), (X_test, y_test)]
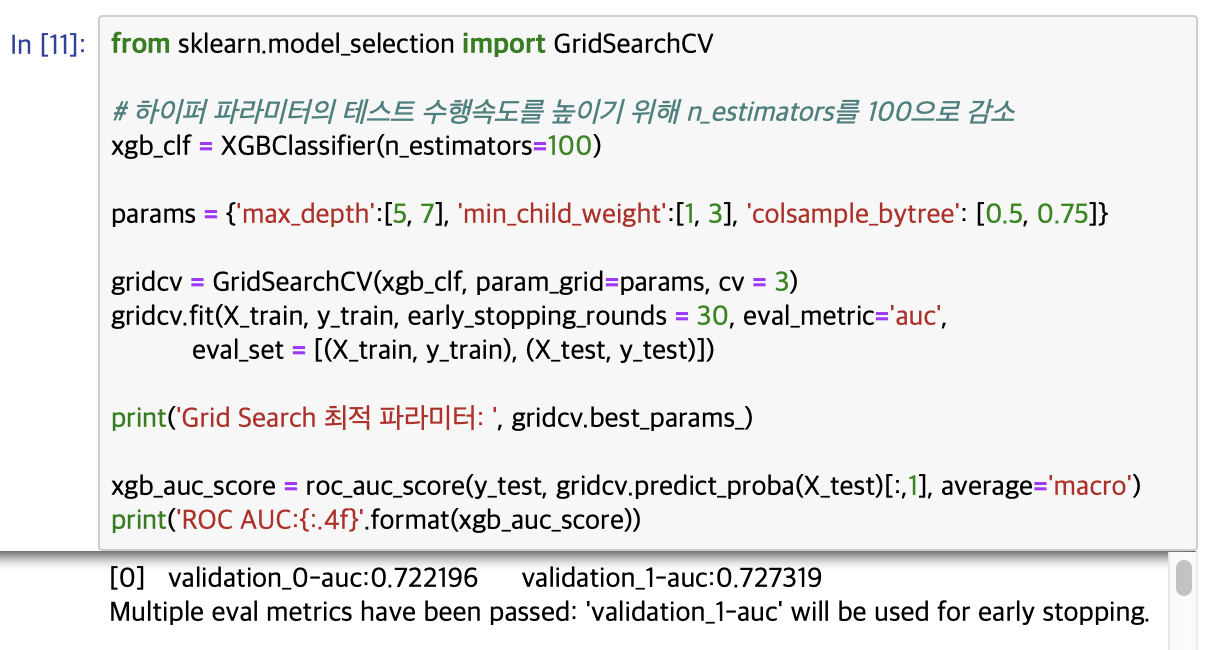
테스트 데이터 세트로 예측시 ROU AUC는 약 0.8419가 나왔습니다. 다음으론 XGBoost의 하이퍼 파라미터 튜닝을 수행해보겠습니다. 컬럼의 수가 많아 과적합 가능성을 가정하고, max_depth, min_child_weight, colsample_bytree만 일차적으로 튜닝하겠습니다. 학습시간이 많이 필요한 ML모델의 경우 2~ 3개 정도의 파라미터를 결합해 최적파라미터를 찾아낸 뒤 이 파라미터를 기반으로 1~2개의 파라미터를 결합해 파라미터 튜닝을 수행하는 것입니다.
뒤의 예제 코드에서는 수행시간이 오래 걸리므로 n_estimators = 100, early_stopping_rounds = 30으로 줄여서 테스트하겠습니다.
파라미터가 위와 같을 때, 처음실행한 0.8419에서 0.8438로 성능이 소폭 좋아졌습니다. 이를 기반으로 n_estimator를 1000으로 증가시키고, learning_rate = 0.02로 감소시켰습니다. 그리고 reg_alpha = 0.03을 추가했습니다.
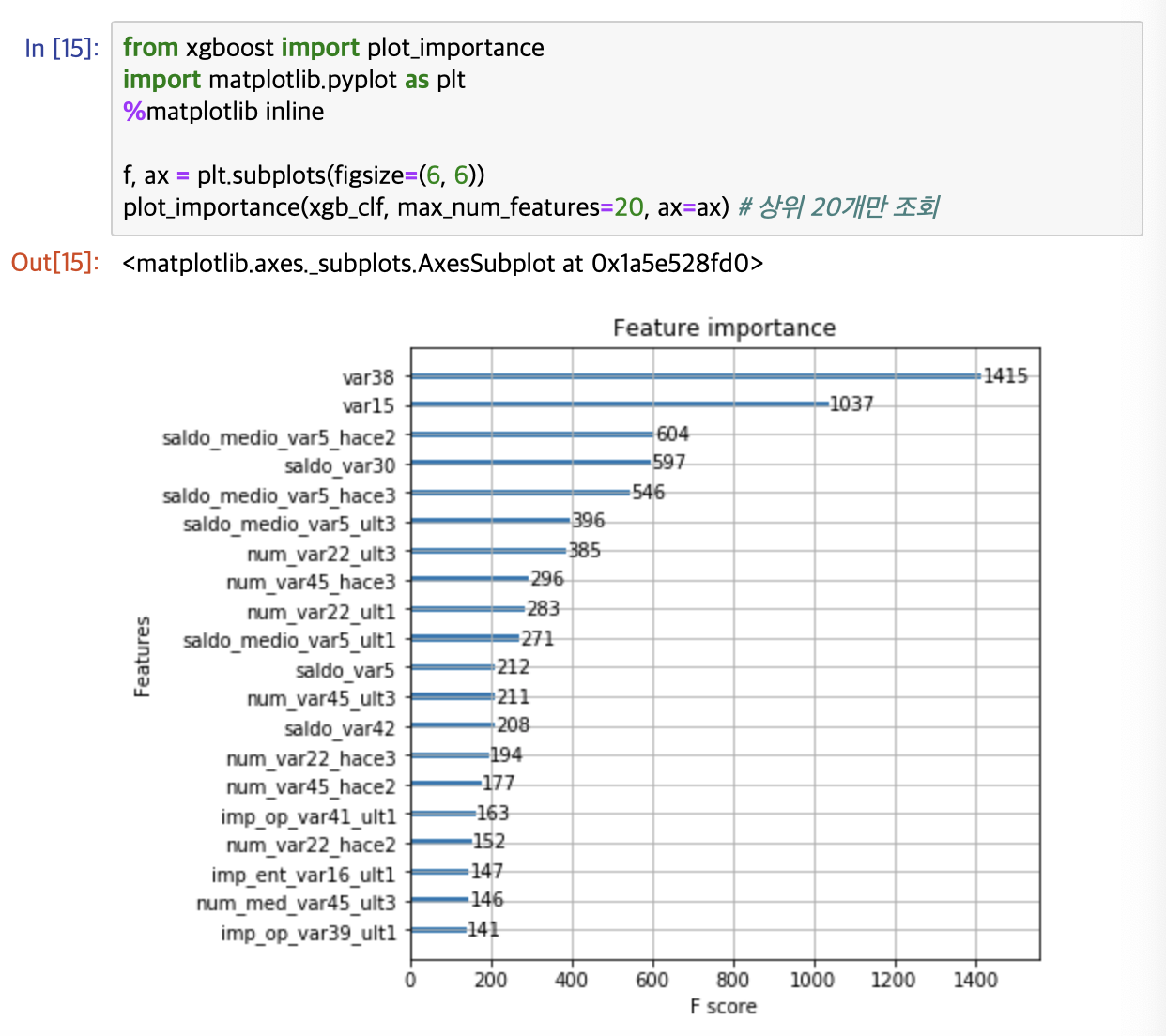
ROC AUC가 0.8441로 이전보다 조금 더 향상되었습니다. 튜닝된 모델에서 피처 중요도를 그래프로 나타내보겠습니다.
Estimator API를 사용하면 매번 코드를 일일이 입력하지 않고도, 위의 도표에 있는 다양한 이점을 활용할 수 있다.
텐서플로는 직접 바로 실행해볼 수 있는 pre-made estimator들을 활용할 수 있다.
2. Pre-made Estimators
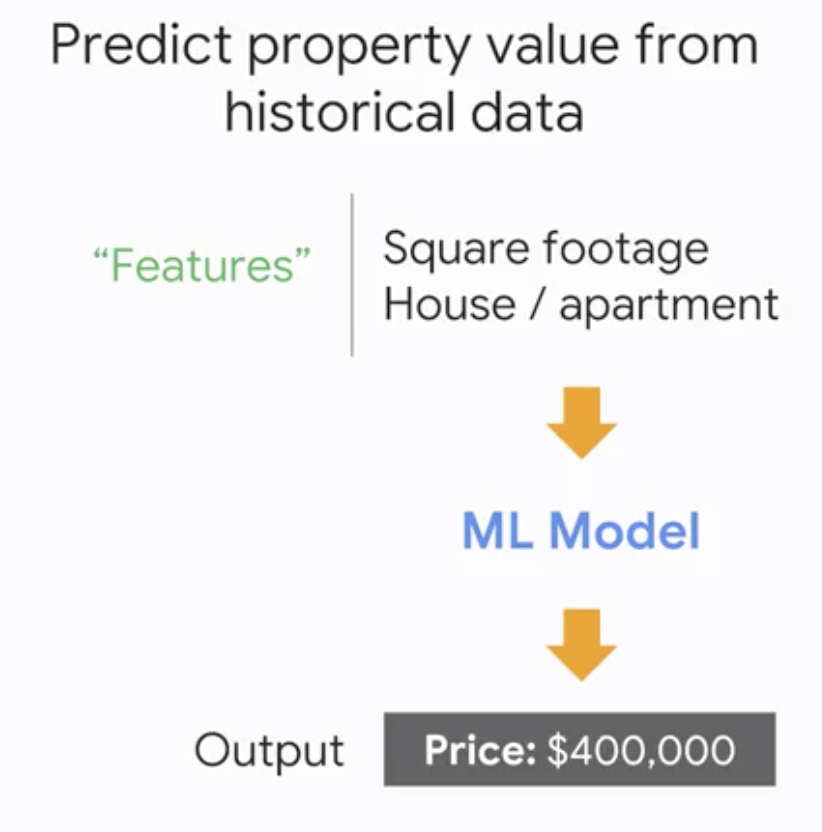
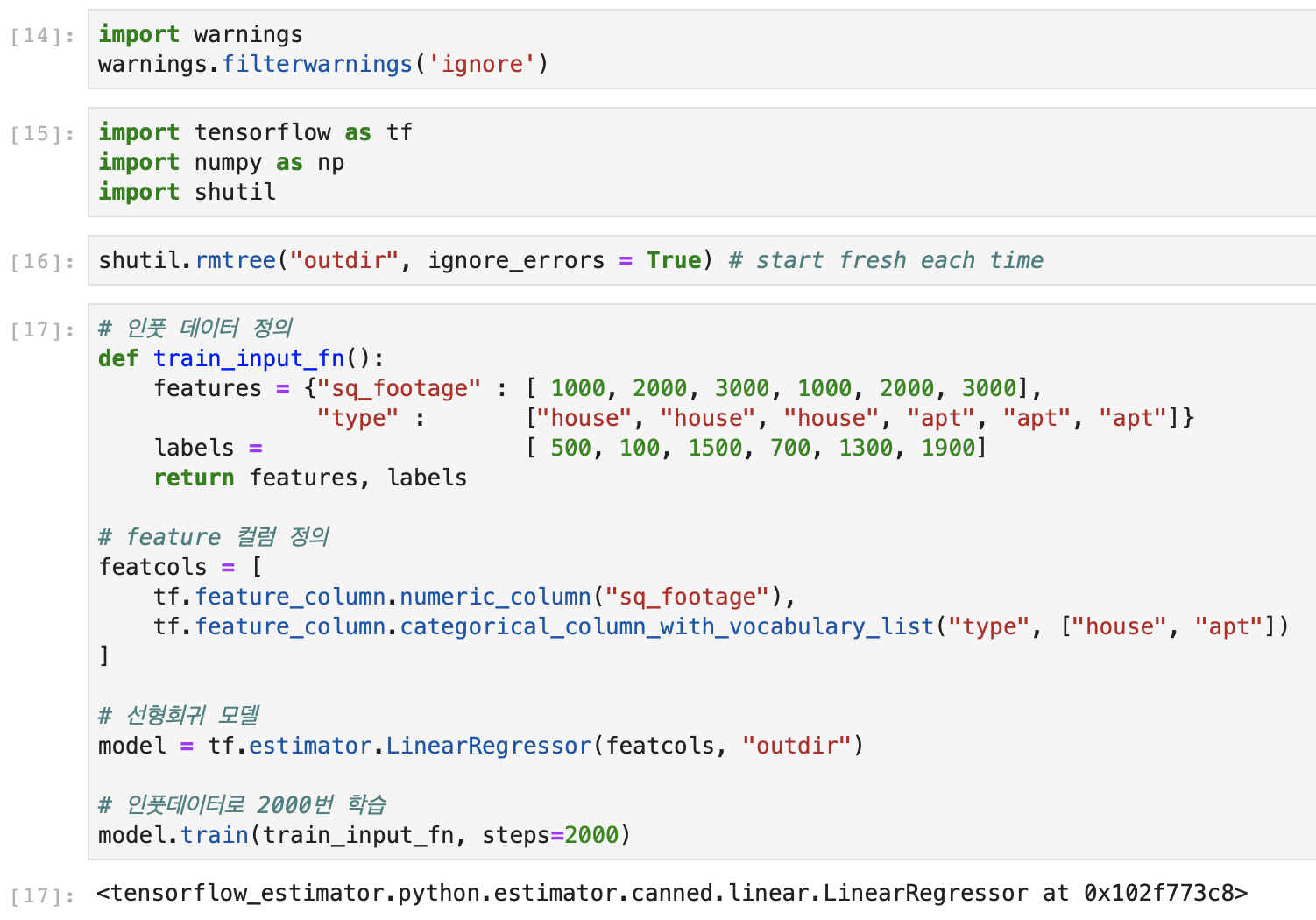
예시를 들어 부동산의 가격을 예측을 하려고 하자. 이 때 우리는 먼저 피처를 선택해야 한다. 이번 예시에서는 집의 면적과 종류를 피처로 사용.
먼저 피처를 정하기 위해 feature_column API를 사용할 수 있다. 이번 예시에서는 numeric column과 categorical column이 하나씩 사용되었다.
그 후에는 모델을 선택하는데 이번 예시에서는 linear regressor가 선택되었다.
선형회귀모델은 데이터의 벡터를 인풋으로 받아들이고, 이 인풋들에 대한 가중치를 조절해나가면서 아웃풋으로 예측 숫자(부동산 가격)을 예측한다.
이번 예시에서는 numeric과 categorical 만을 사용했지만 embedding, crossed 등 더 다양한 형태의 컬럼이 API로 존재한다.
그 후에는 모델에 input 데이터를 넣어, 모델을 학습시킨다. 이번 예제에서는 데이터셋에 대해 100번 반복해서 학습을 한다.
이 후에는 인풋 데이터와는 다른 데이터를 집어넣어 결과를 예측한다.
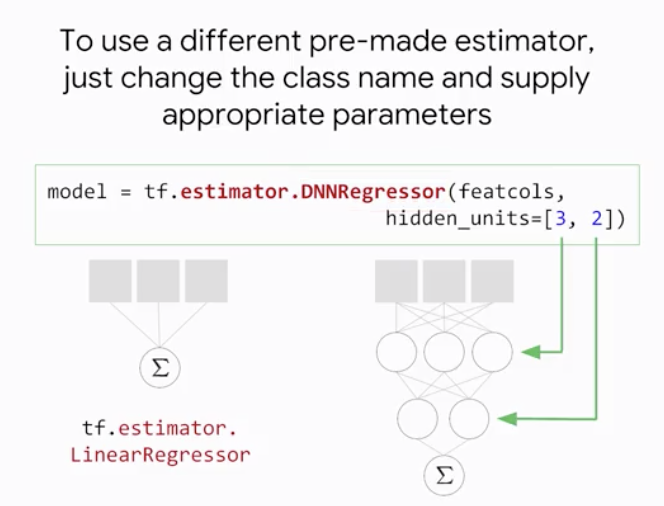
다른 pre-made estimator를 사용하려면 위와 같이 클래스을 변경하고 그에 따른 적절한 파라미터만 적용해주면 된다.
아래는 위의 예시를 반복해서 실행해본 내용
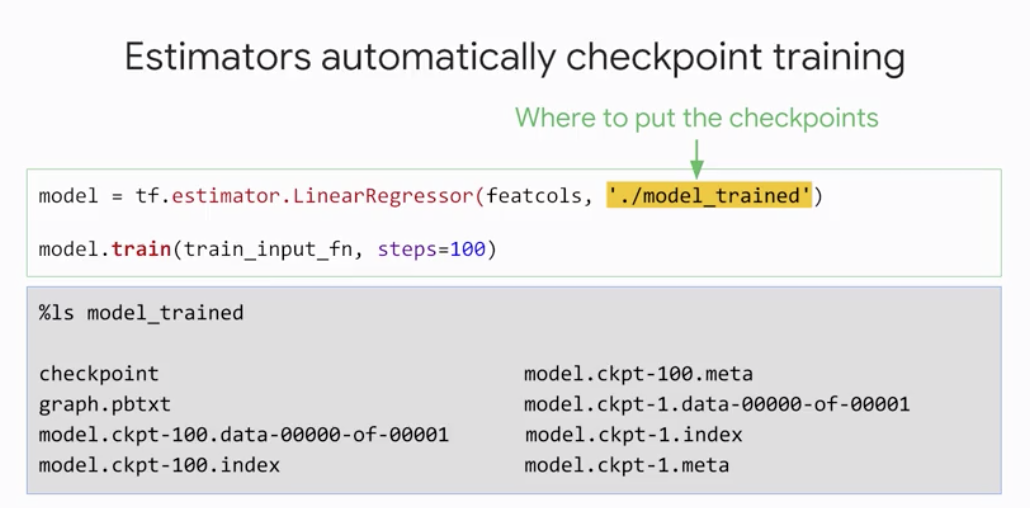
3. Checkpoint
체크포인트는 위와 같이 학습의 지속, 실패로부터의 재개, 학습된 모델로부터의 예측 등을 위해 유용하게 사용된다.
위와 같이 모델을 정의할 때 어디에 체크포인트를 저장할지 경로를 지정해주면 된다.
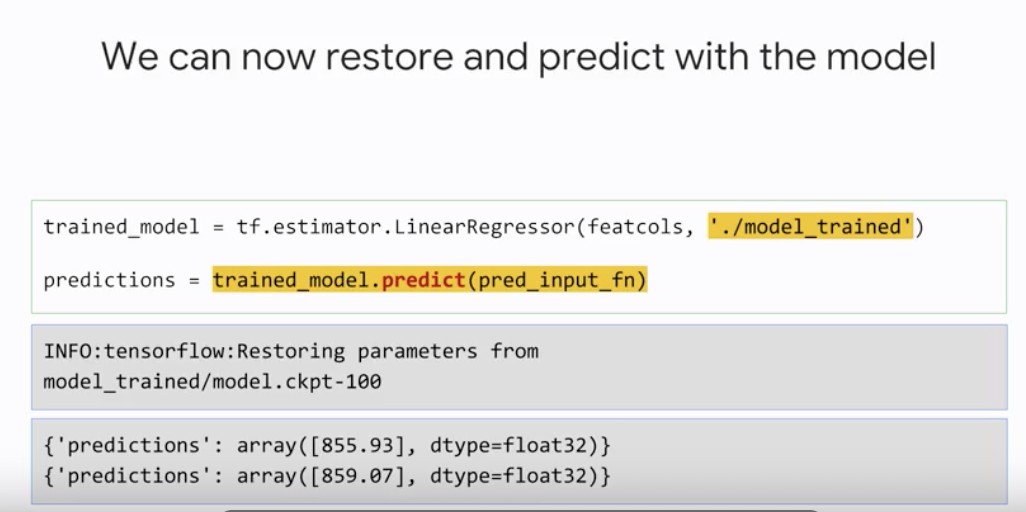
그 후에는 위와 같이 다시 불러와서 저장된 학습된 모델을 가지고 예측을 수행할 수 있다.
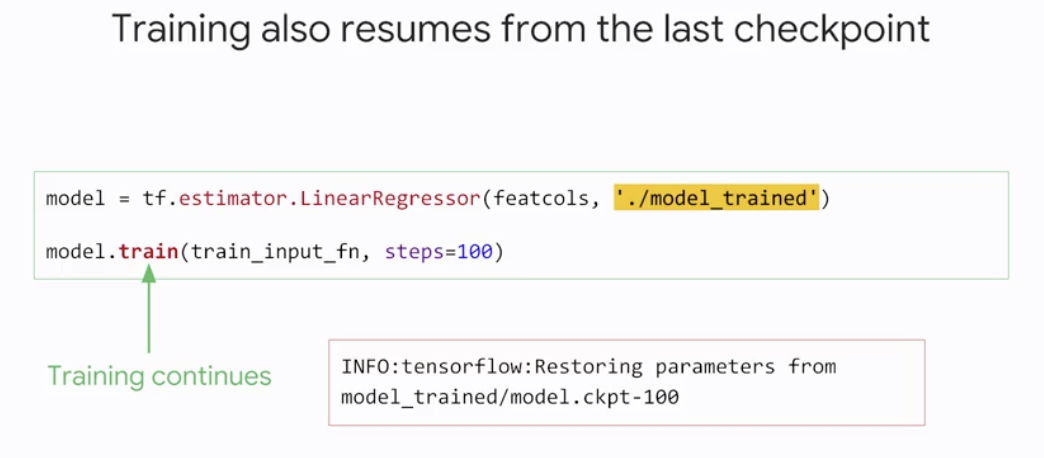
그리고 위와 같이 학습된 데이터를 불러와서 학습을 마저 재개할 수도 있다. 만약 다시 처음부터 다시 학습을 재개하고 싶다면 이 폴더를 삭제하면 된다. 최근의 체크포인트로부터 시작하는 것이 디폴트이기 때문에 학습을 처음부터 다시 수행시키고 싶다면 체크포인트를 반드시 삭제해야한다.
4. Training on in-memory datasets
데이터셋이 numpy array이거나 pandas 이면 Estimator API는 데이터를 입력하는데 편리한 함수를 가지고 있다. estimator.inputs.numpy_input_fn(),estimator.inputs.numpy_input_fn() 위의 예시처럼 피처가 될 x와 레이블이 될 y를 지정해주면 된다.
이 함수들은 뉴럴 네트워크모델 학습에 키가 되는 몇몇 기능들을 가지고 있다. 먼저 배치 사이즈를 조절할 수 있다. →) 전체 데이터셋을 한번에 학습하는 것보다 데이터의 미니 배치를 단계별로 학습하는 것이 통상 좋다. 그리고 데이터 셋을 몇번 반복할 것인지 에포크 숫자를 조절함으로써 세팅할 수 있다. 데이터를 무작위로 섞기도 가능하며, 복제된 데이터셋의 크기 또한 조절이 가능하다.
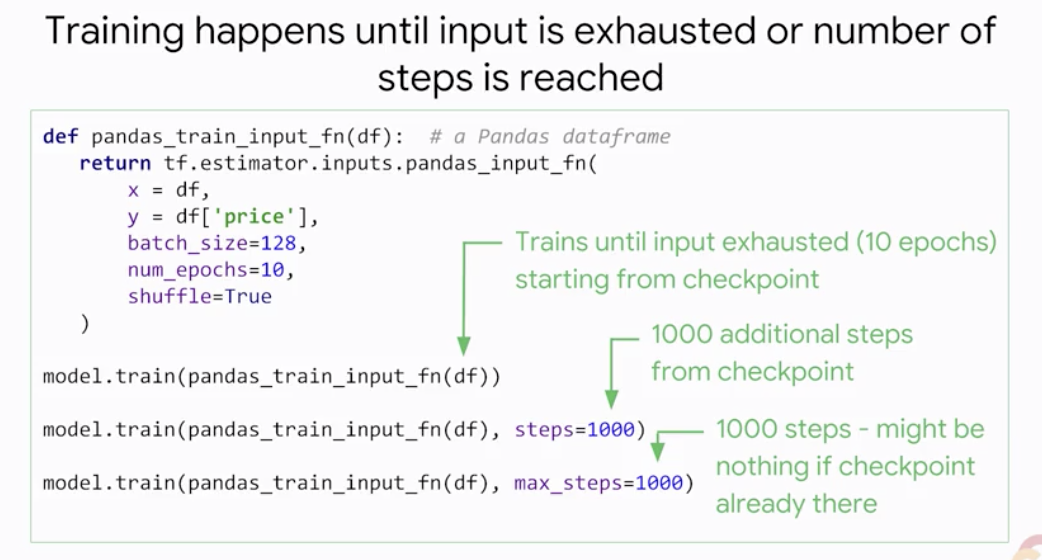
기본적으로 학습은 데이터가 소진되거나 정의한 n 에포크에 도달할 때까지 진행된다. 그리고 학습 함수를 호출할 때, step수를 지정해줌으로써 더 진행할 수도 있다. 위의 예시에서는 마지막 체크포인트에서부터 1000번의 학습스텝을 더 진행한다. 그리고 max_steps에서 지정한 수에 도달하면 학습을 멈추게 할 수도 있다. (하지만 체크포인트가 이미 그 지점까지 와있다면 별 영향이 없다.)