산탄데르 고객만족 예측
https://www.kaggle.com/c/santander-customer-satisfaction
370개의 피처로 이루어진 데이터 세트 기반에서 고객만족 여부를 예측하는 것
피처이름은 모두 익명화되어 있어 어떤 속성인지는 알 수 없습니다.
클래스 레이블명은 TARGET이며 1이면 불만, 0이면 만족한 고객입니다.
모델의 성능평가는 ROC-AUC로 평가합니다.
대부분이 만족이고, 불만족인 데이터는 일부이기 때문에 단순 정확도 수치보다 ROU-AUC가 더 적합합니다.
데이터 전처리

클래스 값 컬럼을 포함하면 총 371개의 피처가 존재합니다.
피처들의 타입과 Null값을 더 살펴보겠습니다.

111개의 피처가 float형, 260개의 피처가 int형이며 NULL 값은 존재하지 않습니다.
다음으로 레이블인 TARGET의 분포를 살펴보겠습니다.

데이터프레임의 describe() 메소드를 사용해 각 피처의 값 분포를 간단히 확인해보겠습니다.

var3의 경우 최소값이 -999999로 나왔는데 1, 2, 3분위 수나 최댓값으로 미루어 보았을 때 결측치로 보입니다.

-999999의 값은 116개로 전체 데이터에 대해 비중이 적으므로 가장 값이 많은 2로 대체하겠습니다.
그리고 ID는 단순 식별자이므로 피처에서 드롭하겠습니다.
그 후에 피처들과 레이블 데이터를 분리해서 별도로 저장하겠습니다.

이후 성능평가를 위해서 현재 데이터 세트를 학습과 테스트 데이터 세트로 분리하겠습니다.
비대칭 데이터 세트이기 때문에 레이블의 분포가 원 데이터와 유사하게 추출되었는지 확인해보겠습니다.

데이터 세트 분할 결과 원 데이터셋과 유사하게 unsatisfied의 비율이 4%에 근접하는 수준이 되었습니다.
XGBoost 모델 학습과 하이퍼 파라미터 튜닝
XGBoost로 기본 세팅을 아래와 설정하고, 예측결과를 ROC-AUC로 평가해보겠습니다.
n_estimators = 500
early_stopping_rounds = 100
eval_metric = 'auc'
평가 데이터세트는 앞에서 분리한 테스트 데이터 세트를 이용하겠습니다.
테스트 데이터 세트를 XGBoost의 평가 데이터 세트로 사용하면 과적합이 될 우려가 있지만, 일단 진행하겠습니다.
eval_set = [(X_train, y_train), (X_test, y_test)]


테스트 데이터 세트로 예측시 ROU AUC는 약 0.8419가 나왔습니다.
다음으론 XGBoost의 하이퍼 파라미터 튜닝을 수행해보겠습니다.
컬럼의 수가 많아 과적합 가능성을 가정하고, max_depth, min_child_weight, colsample_bytree만
일차적으로 튜닝하겠습니다.
학습시간이 많이 필요한 ML모델의 경우 2~ 3개 정도의 파라미터를 결합해 최적파라미터를 찾아낸 뒤
이 파라미터를 기반으로 1~2개의 파라미터를 결합해 파라미터 튜닝을 수행하는 것입니다.
뒤의 예제 코드에서는 수행시간이 오래 걸리므로
n_estimators = 100, early_stopping_rounds = 30으로 줄여서 테스트하겠습니다.


파라미터가 위와 같을 때, 처음실행한 0.8419에서 0.8438로 성능이 소폭 좋아졌습니다.
이를 기반으로 n_estimator를 1000으로 증가시키고, learning_rate = 0.02로 감소시켰습니다.
그리고 reg_alpha = 0.03을 추가했습니다.


ROC AUC가 0.8441로 이전보다 조금 더 향상되었습니다.
튜닝된 모델에서 피처 중요도를 그래프로 나타내보겠습니다.

'Machine Learning > 파이썬 머신러닝 완벽가이드 학습' 카테고리의 다른 글
| [Chapter 4. 분류] LightGBM (1) | 2019.11.03 |
|---|---|
| [Chapter 4. 분류] XGBoost(eXtraGradient Boost) (3) | 2019.10.27 |
| [Chapter 4. 분류] 부스팅알고리즘(AdaBoost, GBM) (0) | 2019.10.20 |
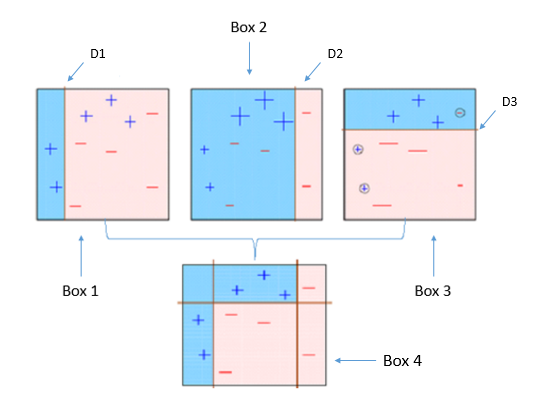
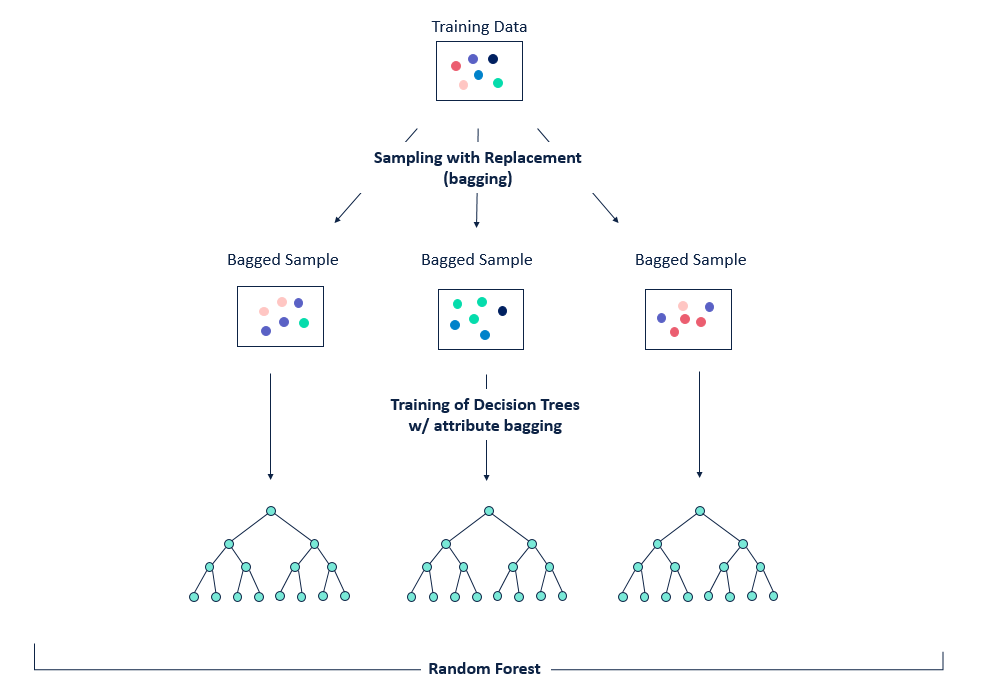
| [Chapter 4. 분류] 랜덤포레스트(Random Forest) (1) | 2019.10.19 |
| [Chapter 4. 분류] 앙상블 학습 (0) | 2019.10.14 |