from IPython.core.display import display, HTML
display(HTML("<style> .container{width:90% !important;}</style>"))
1. Boosting Algorithm¶
부스팅 알고리즘은 여러 개의 약한 학습기(weak learner)를 순차적으로 학습-예측하면서 잘못 예측한 데이터에 가중치를 부여해 오류를 개선해나가며 학습하는 방식
부스팅 알고리즘은 대표적으로 아래와 같은 알고리즘들이 있음
- AdaBoost
- Gradient Booting Machine(GBM)
- XGBoost
- LightGBM
- CatBoost
2. AdaBoost¶
Adaptive Boost의 줄임말로서 약한 학습기(weak learner)의 오류 데이터에 가중치를 부여하면서 부스팅을 수행하는 대표적인 알고리즘
속도나 성능적인 측면에서 decision tree를 약한 학습기로 사용함
AdaBoost의 학습¶
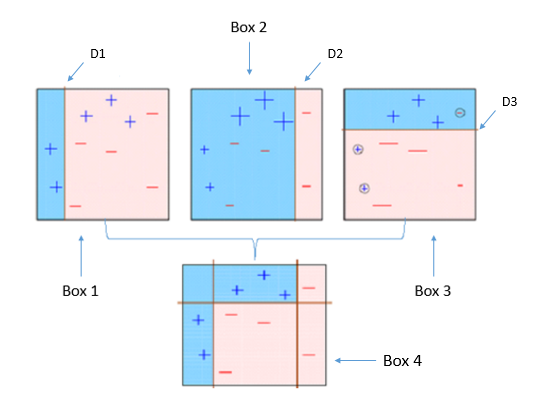
Step 1) 첫 번째 약한 학습기가 첫번째 분류기준(D1)으로 + 와 - 를 분류
Step 2) 잘못 분류된 데이터에 대해 가중치를 부여(두 번쨰 그림에서 커진 + 표시)
Step 3) 두 번째 약한 학습기가 두번째 분류기준(D2)으로 +와 - 를 다시 분류
Step 4) 잘못 분류된 데이터에 대해 가중치를 부여(세 번째 그림에서 커진 - 표시)
Step 5) 세 번째 약한 학습기가 세번째 분류기준으로(D3) +와 -를 다시 분류해서 오류 데이터를 찾음
Step 6) 마지막으로 분류기들을 결합하여 최종 예측 수행
→ 약한 학습기를 순차적으로 학습시켜, 개별 학습기에 가중치를 부여하여 모두 결합함으로써 개별 약한 학습기보다 높은 정확도의 예측 결과를 만듦
AdaBoost의 실행코드¶
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
import warnings
warnings.filterwarnings('ignore')
# 데이터셋을 구하는 함수 설정
def get_human_dataset():
# 각 데이터 파일들은 공백으로 분리되어 있으므로 read_csv에서 공백문자를 sep으로 할당
feature_name_df = pd.read_csv('human_activity/features.txt', sep='\s+',
header=None, names=['column_index', 'column_name'])
# 데이터프레임에 피처명을 컬럼으로 뷰여하기 위해 리스트 객체로 다시 반환
feature_name = feature_name_df.iloc[:, 1].values.tolist()
# 학습 피처 데이터세트와 테스트 피처 데이터를 데이터프레임으로 로딩
# 컬럼명은 feature_name 적용
X_train = pd.read_csv('human_activity/train/X_train.txt', sep='\s+', names=feature_name)
X_test = pd.read_csv('human_activity/test/X_test.txt', sep='\s+', names=feature_name)
# 학습 레이블과 테스트 레이블 데이터를 데이터 프레임으로 로딩, 컬럼명은 action으로 부여
y_train = pd.read_csv('human_activity/train/y_train.txt', sep='\s+', names=['action'])
y_test = pd.read_csv('human_activity/test/y_test.txt', sep='\s+', names=['action'])
# 로드된 학습/테스트용 데이터프레임을 모두 반환
return X_train, X_test, y_train, y_test
# 학습/테스트용 데이터 프레임 반환
X_train, X_test, y_train, y_test = get_human_dataset()
from sklearn.ensemble import AdaBoostClassifier
from sklearn.metrics import accuracy_score
clf = AdaBoostClassifier(n_estimators=30,
random_state=10,
learning_rate=0.1)
clf.fit(X_train, y_train)
pred = clf.predict(X_test)
print('AdaBoost 정확도: {:.4f}'.format(accuracy_score(y_test, pred)))
AdaBoost의 하이퍼파라미터¶
| 파라미터 명 | 설명 |
|---|---|
| base_estimators | - 학습에 사용하는 알고리즘 - Default = None → DecisionTreeClassifier(max_depth=1)가 적용 |
| n_estimators | - 생성할 약한 학습기의 갯수를 지정 - Default = 50 |
| learning_rate | - 학습을 진행할 때마다 적용하는 학습률(0~1) - Weak learner가 순차적으로 오류 값을 보정해나갈 때 적용하는 계수 - Default = 1.0 |
- n_estimators를 늘린다면
- 생성하는 weak learner의 수는 늘어남
- 이 여러 학습기들의 decision boundary가 많아지면서 모델이 복잡해짐
- learning_rate을 줄인다면
- 가중치 갱신의 변동폭이 감소해서, 여러 학습기들의 decision boundary 차이가 줄어듦
위의 두 가지는 trade-off 관계입니다.
n_estimators(또는 learning_rate)를 늘리고, learning_rate(또는 n_estimators)을 줄인다면 서로 효과가 상쇄됩다.
→ 때문에 이 두 파라미터를 잘 조정하는 것이 알고리즘의 핵심입니다.
3. Gradient Boost Machine(GBM)¶
GBM의 학습 방식¶
AdaBoost와 유사하지만, 가중치 업데이트를 경사하강법(Gradient Descent)를 이용하여 최적화된 결과를 얻는 알고리즘입니다.
GBM은 예측 성능이 높지만 Greedy Algorithm으로 과적합이 빠르게되고, 시간이 오래 걸린다는 단점이 있습니다.
※ 경사하강법
분류의 실제값을 y, 피처에 기반한 예측함수를 F(x), 오류식을 h(x) = y-F(x)라고 하면 이 오류식을 최소화하는 방향성을 가지고 가중치 값을 업데이트
※ Greedy Algorithm(탐욕 알고리즘)
미래를 생각하지 않고 각 단계에서 가장 최선의 선택을 하는 기법으로
각 단계에서 최선의 선택을 한 것이 전체적으로도 최선이길 바라는 알고리즘입니다.
물론 모든 경우에서 그리디 알고리즘이 통하지는 않습니다.
가령 지금 선택하면 1개의 마시멜로를 받고, 1분 기다렸다 선택하면 2개의 마시멜로를 받는 문제에서는,
그리디 알고리즘을 사용하면 항상 마시멜로를 1개밖에 받지 못합니다.
지금 당장 최선의 선택은 마시멜로 1개를 받는 거지만, 결과적으로는 1분 기다렸다가 2개 받는 게 최선이기 때문입니다.
( 설명출처: https://www.zerocho.com/category/Algorithm/post/584ba5c9580277001862f188 )
# Gradient Boosting Classifier 불러오기
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.metrics import accuracy_score
import time
# GBM 수행시간 측정을 위함. 시작시간 설정
start_time = time.time()
# 예시 데이터셋 불러오기
gb_clf = GradientBoostingClassifier(random_state=0)
gb_clf.fit(X_train, y_train.values)
gb_pred = gb_clf.predict(X_test)
gb_accuracy = accuracy_score(y_test, gb_pred)
print('GBM 정확도: {:.4f}'.format(gb_accuracy))
print('GBM 수행 시간: {:.1f}초'.format(time.time() - start_time))
GBM의 하이퍼파라미터¶
Tree에 관한 하이퍼 파라미터¶
| 파라미터 명 | 설명 |
|---|---|
| max_depth | - 트리의 최대 깊이 - default = 3 - 깊이가 깊어지면 과적합될 수 있으므로 적절히 제어 필요 |
| min_samples_split | - 노드를 분할하기 위한 최소한의 샘플 데이터수 → 과적합을 제어하는데 사용 - Default = 2 → 작게 설정할 수록 분할 노드가 많아져 과적합 가능성 증가 |
| min_samples_leaf | - 리프노드가 되기 위해 필요한 최소한의 샘플 데이터수 - min_samples_split과 함께 과적합 제어 용도 - default = 1 - 불균형 데이터의 경우 특정 클래스의 데이터가 극도로 작을 수 있으므로 작게 설정 필요 |
| max_features | - 최적의 분할을 위해 고려할 최대 feature 개수 - Default = 'none' → 모든 피처 사용 - int형으로 지정 →피처 갯수 / float형으로 지정 →비중 - sqrt 또는 auto : 전체 피처 중 √(피처개수) 만큼 선정 - log : 전체 피처 중 log2(전체 피처 개수) 만큼 선정 |
| max_leaf_nodes | - 리프노드의 최대 개수 - default = None → 제한없음 |
Boosting에 관한 하이퍼파라미터¶
| 파라미터 명 | 설명 |
|---|---|
| loss | - 경사하강법에서 사용할 cost function 지정 - 특별한 이유가 없으면 default 값인 deviance 적용 |
| n_estimators | - 생성할 트리의 갯수를 지정 - Default = 100 - 많을소록 성능은 좋아지지만 시간이 오래 걸림 |
| learning_rate | - 학습을 진행할 때마다 적용하는 학습률(0~1) - Weak learner가 순차적으로 오류 값을 보정해나갈 때 적용하는 계수 - Default = 0.1 - 낮은 만큼 최소 오류 값을 찾아 예측성능이 높아질 수 있음 - 하지만 많은 수의 트리가 필요하고 시간이 많이 소요 |
| subsample | - 개별 트리가 학습에 사용하는 데이터 샘플링 비율(0~1) - default=1 (전체 데이터 학습) - 이 값을 조절하여 트리 간의 상관도를 줄일 수 있음 |
GridSearchCV를 통한 GBM의 하이퍼파라미터 튜닝¶
from sklearn.model_selection import GridSearchCV
param = {
'n_estimators' : [100, 500],
'learning_rate' : [0.05, 0.1]
}
grid_cv = GridSearchCV(gb_clf, param_grid=param, cv=2, verbose=1, n_jobs=-1)
grid_cv.fit(X_train, y_train.values)
print('최적 하이퍼 파라미터: \n', grid_cv.best_params_)
print('최고 예측 정확도: {0:.4f}'.format(grid_cv.best_score_))
위의 간단한 그리드서치에서는 learning_rate = 0.05, n_estimator = 500 일 때 , 90.1% 정확도가 최고로 도출되었습니다.
# GridSearchCV를 이용해 최적으로 학습된 estimators로 예측 수행
gb_pred = grid_cv.best_estimator_.predict(X_test)
gb_accuracy = accuracy_score(y_test, gb_pred)
print('GBM 정확도: {0:.4f}'.format(gb_accuracy))
테스트 데이터 세트에서 약 94.03%의 정확도를 나타냈습니다.
'Machine Learning > 파이썬 머신러닝 완벽가이드 학습' 카테고리의 다른 글
| [Chapter 4. 분류] LightGBM (1) | 2019.11.03 |
|---|---|
| [Chapter 4. 분류] XGBoost(eXtraGradient Boost) (3) | 2019.10.27 |
| [Chapter 4. 분류] 랜덤포레스트(Random Forest) (1) | 2019.10.19 |
| [Chapter 4. 분류] 앙상블 학습 (0) | 2019.10.14 |
| [Chapter 4. 분류] Decision Tree Classifier (0) | 2019.10.03 |