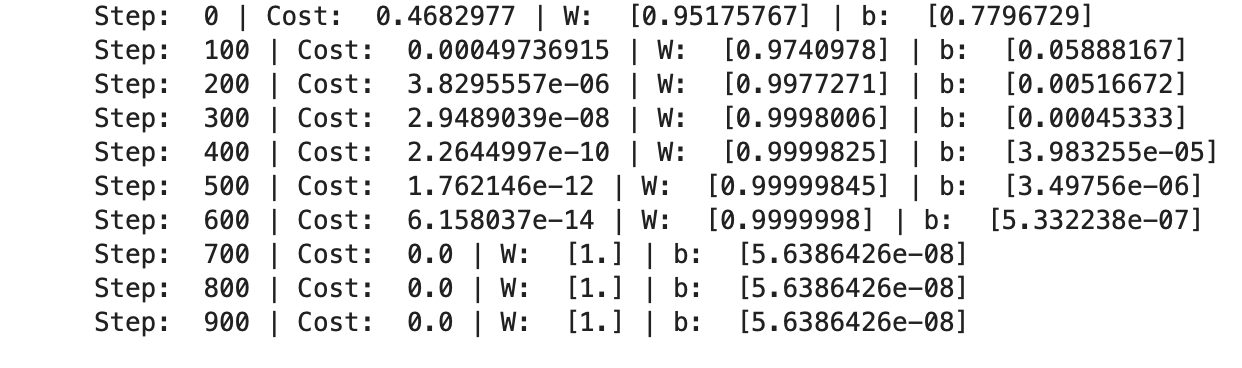
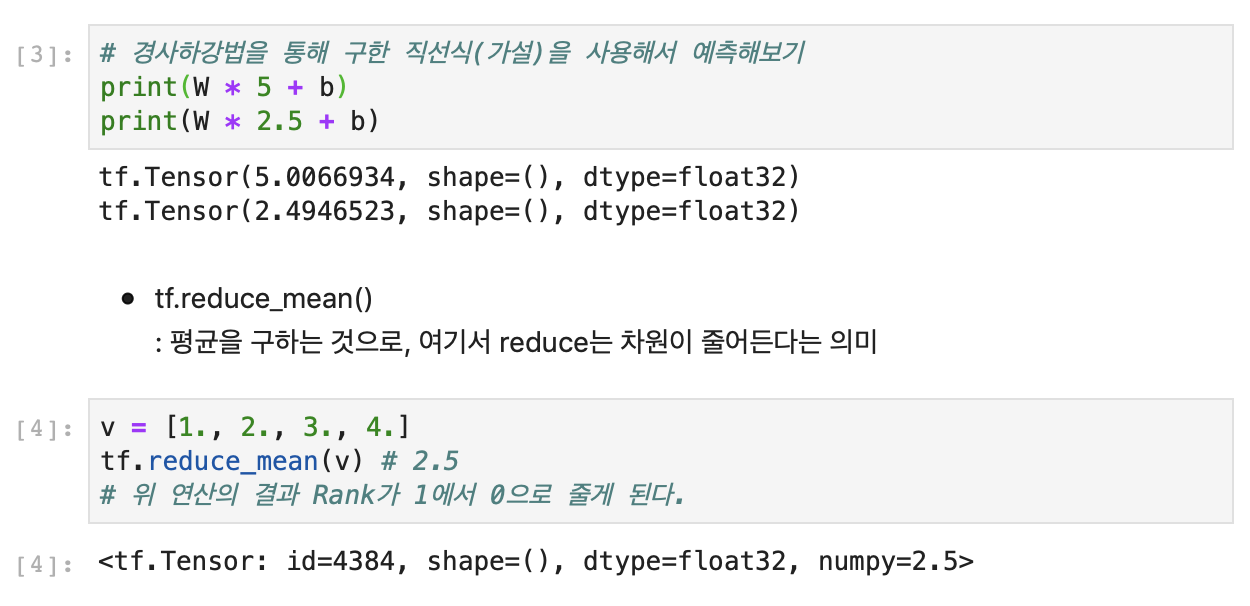
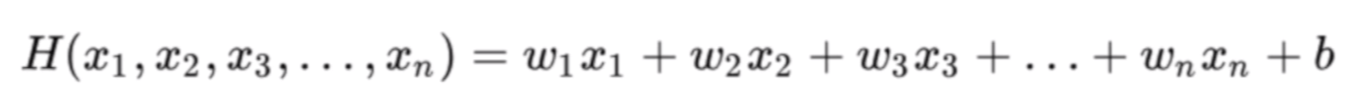의미 : Regression toward the mean → 데이터들은 전체의 평균으로 되돌아가려는 특징이 있다는 의미
2. Linear Regression
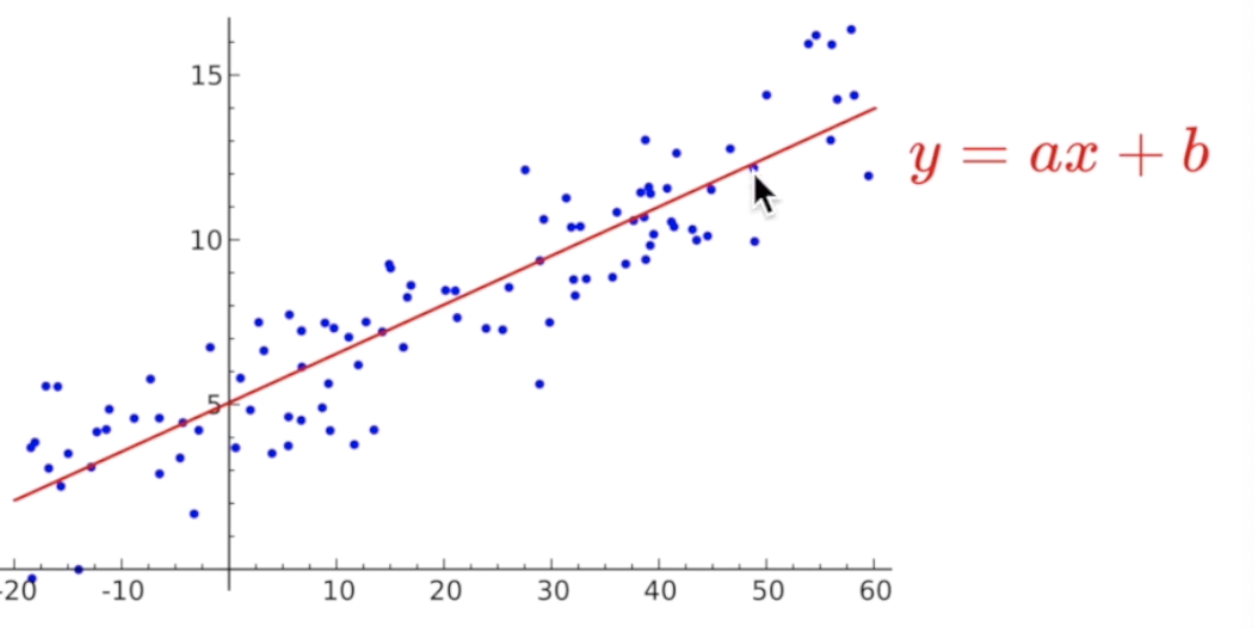
데이터(아래의 파란색 점)를 가장 잘 대변하는 직선의 방정식을 찾는 것(기울기와 절편을 찾는 것)
3. Hypothesis
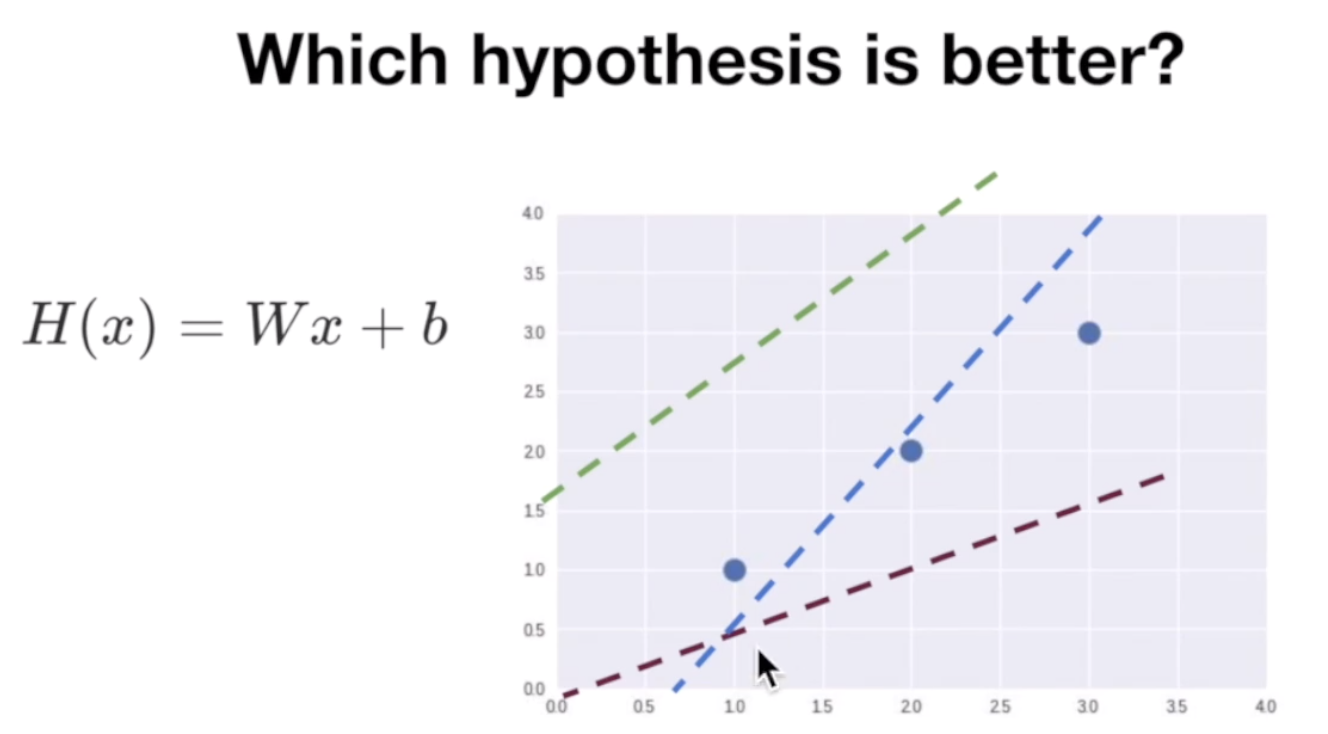
데이터를 대변하는 것으로 생각되는 직선의 식(가설)을 H(x) = Wx + b 라고 한다. 이 때의 W를 Weight, b를 bias라고 한다.
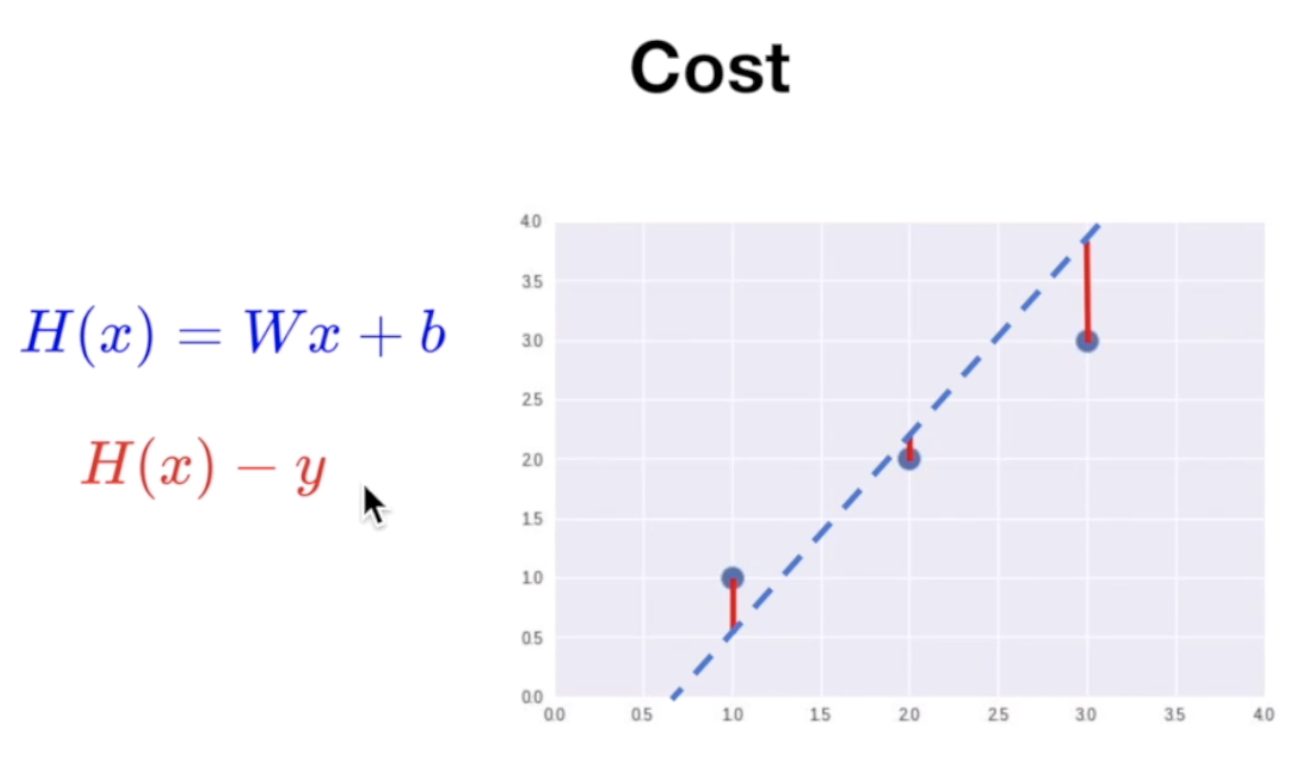
위 그래프의 파란 세점을 나타내는 세 개의 선이 있다고 하자. 이 경우에는 파란색 점선이 가장 이 점들을 잘 나타내는 것으로 보인다. 이 때의 W와 b를 어떻게 정의할 수 있을까?
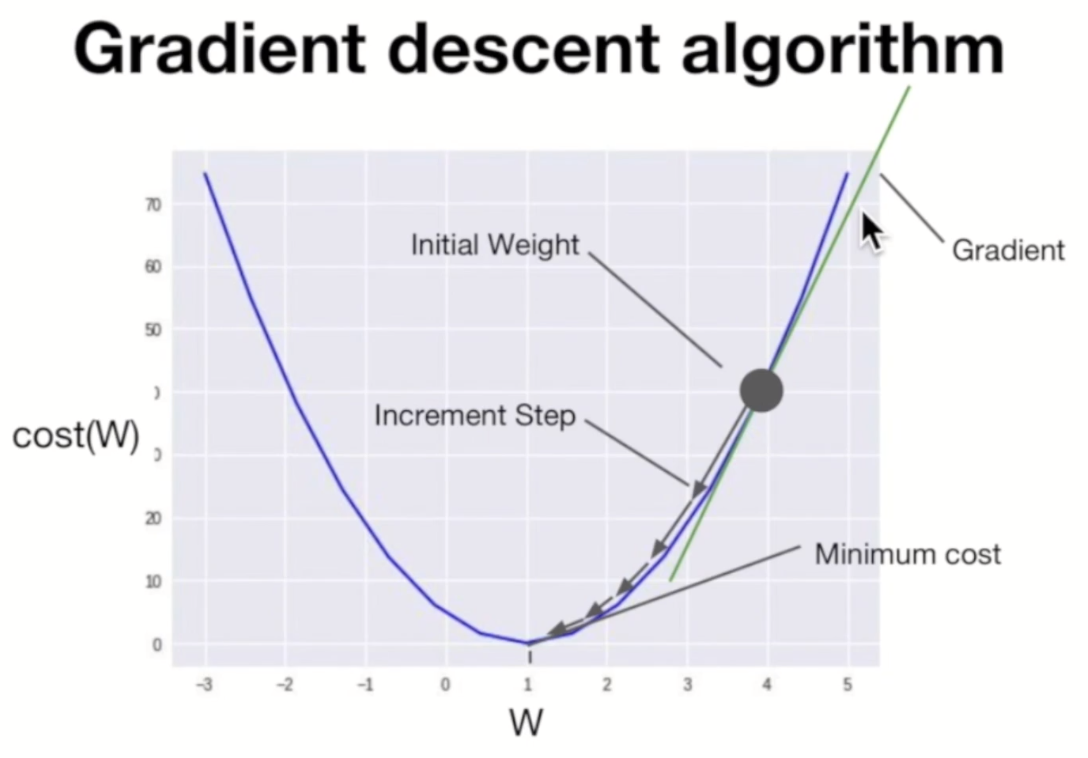
4. Cost
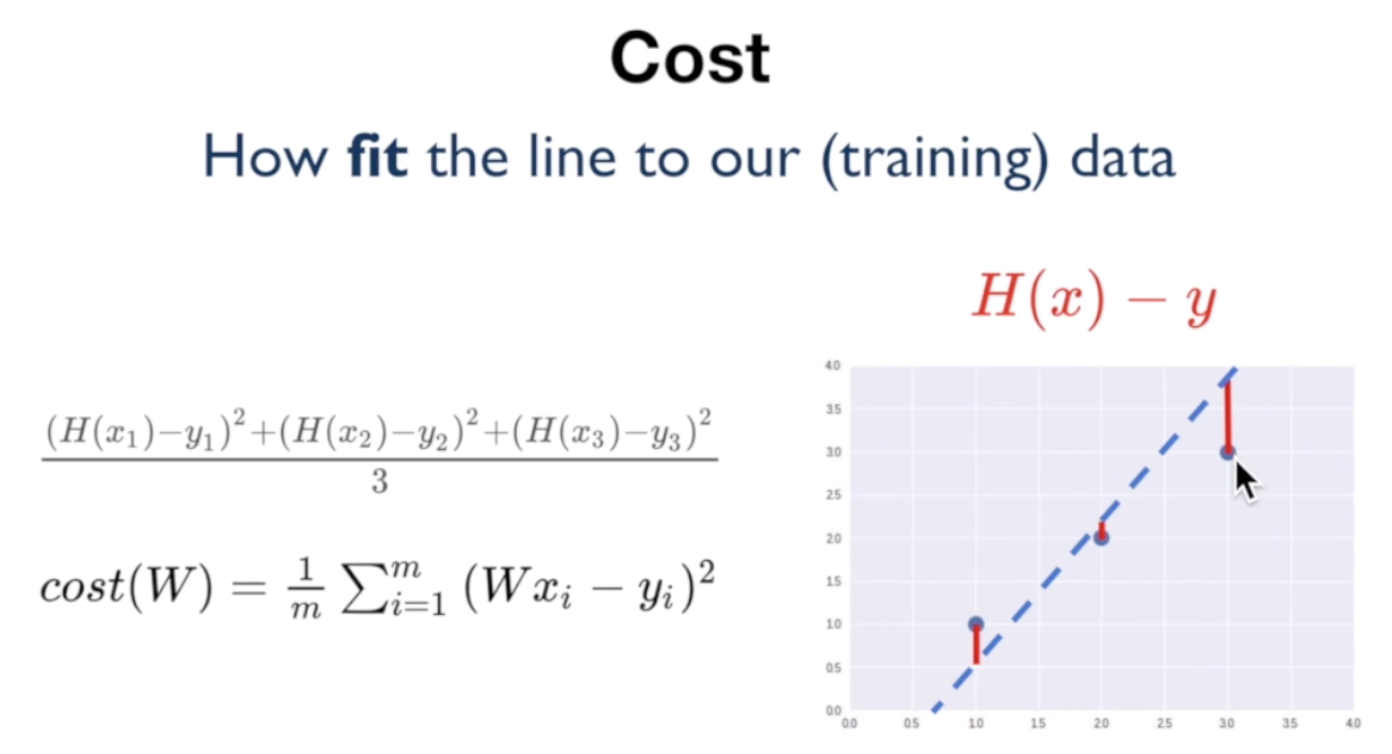
H(x) = Wx + b의 W와 b값을 찾기 위해 Cost라는 개념을 도입하게 된다. 위의 그래프에서 가설의 그래프가 실제 데이터(점)과의 거리, H(x)-y를 Error 혹은 Cost라고 한다. 이 Cost가 작을수록 점선(가설)이 데이터를 잘 대변한다고 볼 수 있다.
그런데 이 때, 단순히 합을 최소화하고자 할 때, 데이터에 따라 Cost 값이 양수일수도 음수일수도 있다. 실제 데이터와 차이가 많이 나더라도, 양수와 음수 값이 서로 상쇄해서 Cost가 적은 것처럼 보일 수 있다. 이 점을 보완하기 위해서 각 Error의 제곱을 합산해서 이 값의 최소값을 구하는 방식이 많이 사용된다.
가설의 비용함수(Cost function)을 아래와 같이 나타낼 수 있다.
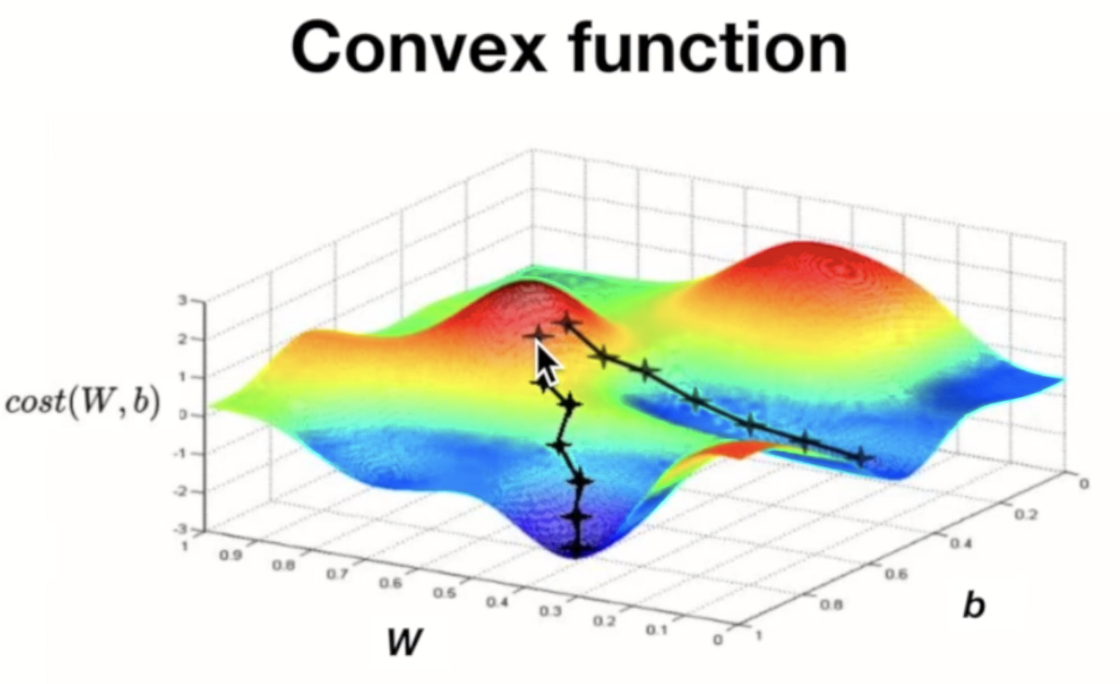
이 때 W와 b의 함수인 비용함수를 최소화하는 것이 선형회귀에서의 우리의 목표라 할 수 있다.