
위의 그래프는 팁 금액을 레이블로 한 ML 모델의 예시
(계산금액와 성별은 이를 추정하기 위한 피처)
여기서 팁 금액은 연속형이기 때문에, 회귀문제에 해당함
회귀문제에서는 피쳐들의 조합으로 이루어진 수학적인 함수를 이용하여 레이블 값을 예측하는 것
모델이 위 그래프에서 초록색 선으로 계산금액과 선의 기울기의 곱으로 레이블 값을 구한다.
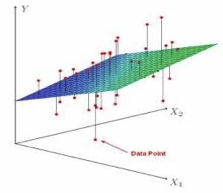
하나가 아닌 여러 개의 피처를 이용하는 다차원의 문제에서도 개념은 동일함
각 개별 데이터의 피처 값에 하이퍼플레인(Hyperplane)의 기울기가 곱해지면서,
레이블의 일반화된 값을 구한다.
(※ 하이퍼플레인(Hyperplane)은 1차원 이상 공간에서의 모델링된 평면을 이야기함)
선형회귀 문제에서는 모델을 일반화하기 위해 예측된 값들과 레이블 값의 거리(에러)를 최소화하려고 함.
이 때 자주 사용되는 것이 MSE(Mean Squared Error)이다.

위의 예시에서 성별을 레이블로, 계산금액과 팁 금액을 피쳐로 분류 문제가 된다.
하지만 이 경우 남성과 여성의 관측값이 잘 분리 되어 있지 않기 때문에 좋은 접근은 아님.
분류 문제에서는 레이블의 연속적인 값을 구하는 것이 아니라 각각 레이블 값을 나누는
결정 경계(decision boundary)를 만들려고 한다.
이 경우 클래스 값이 두개가 존재하고, 결정경계는 차원에 따라 선이나 하이퍼플레인으로 만들어짐.
위의 예시에서는 빨간 선이 결정 경계임.
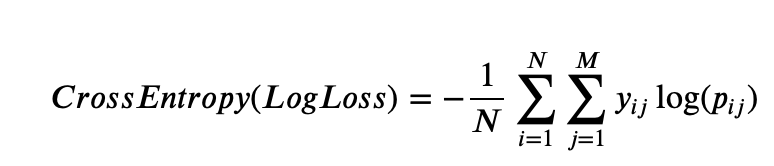
분류문제에서는 예측 클래스와 레이블 클래스 간의 에러를 최소화하기 위해
Cross Entropy(Log Loss)를 사용한다.
여기서 N은 데이터 갯수, M은 레이블 갯수,
y는 정답(0또는 1)을 나타내며 p는 예측값의 확률(0~1)사이
예측 값이 맞을 경우 log1 이 되기 되고 틀린 값으로 예측할수록 Cross Entropy의 값은 높아짐
하지만 팁 금액을 측정하는 경우라도, 반드시 회귀문제가 되는 것은 아님. 팁 크기를 범주화해서
25%~ 일 때는 "High" , 15 ~ 25% 일 때는 "Average", ~15% 일 때는 "Low" 로 만든다면
분류 문제가 될 수 있다.
그 반대의 경우로 카테고리형의 피처도 연속형으로 변경될 수 있다.
결국 어떻게 문제를 해결하려고 하는지에 달려있는 것으로,
머신러닝은 결국 실험에 관한 것이다.
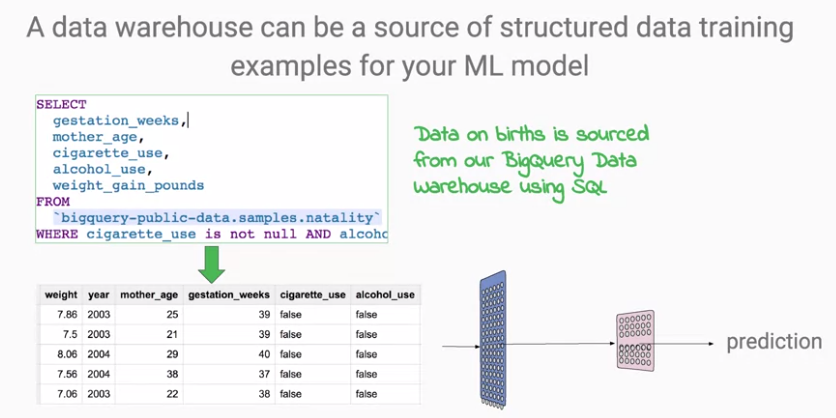
그렇다면 머신러닝에 이용하는 데이터는 어디에서 오는가?
앞의 팁 데이터셋은 흔히 행과 열로 표현되는 "구조화된" 데이터이다.
(흔히 DB에서 조회하는 테이블 같은 것)
머신러닝에서 흔히 사용되는 구조화된 데이터는 Data Warehouse에서 나옴.
"비구조화"된 데이터는 사진, 오디오와 비디오 등과 같은 것.
위의 표는 출생에 관한 공개 데이터 셋으로 빅쿼리에서 제공됨.
SQL을 통해 구조화 데이터를 불러오고, mother_age와 gestation_weeks 등의 피쳐를 활용하고,
모델을 생성하여 아이가 언제 태어날 지를 회귀 문제로 예측할 수 있음
이 외에도 아이 몸무게 등을 레이블로 설정하여 여러 값을 예측할 수 있다.
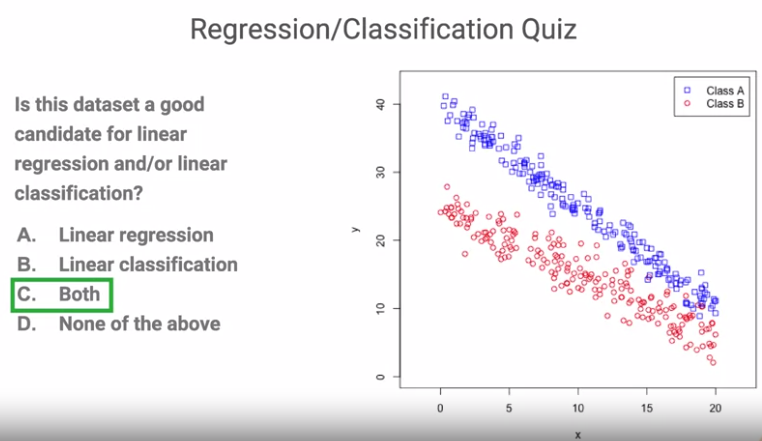
위의 데이터셋은 선형회귀와 분류 모두에 적합한 형태를 띄고 있다.

위의 빨간선과 파란선은 Class A와 Class B의 x와 y에 대한 모델이 된다.
하지만 이를 모두 아우르는 일반적인 모델을 얻고자 한다면 초록색 선이 일반화된 모델로
MSE에 의해 모델의 예측값과 실제 값 사이의 손실이 최소화되는 선이다.
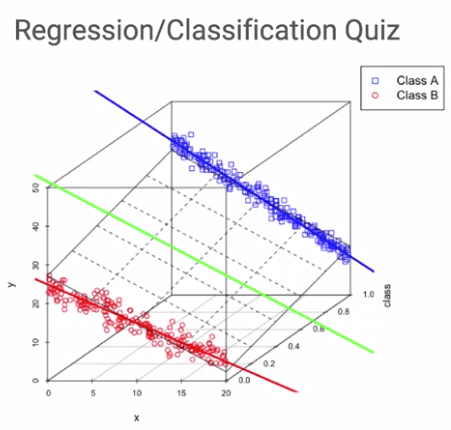
빨간색과 파란색을 아우르는 모델을 도출하기 위해 여러 피처를 사용해서 더 고차원 적으로 접근할 수 있음.
그 경우 위의 그림에서처럼 2d 선형회귀의 결과인 하이퍼플레인이 만들어진다.
이 때, 이 2차원인 하이퍼플레인은 빨간 선과 파란 선, 그리고 그 중간의 초록색 선까지 모두 포괄한다.
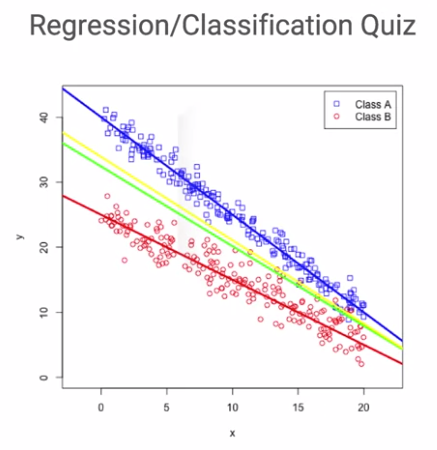
동일한 예시를 분류문제로 보았을 때, Class A와 Class B 를 구분하는 선은 노란선이다.
이 경우 회귀에서 사용한 초록선과 일치하지 않는다.
그 이유는 무엇일까?
회귀모델에서의 손실함수는 MSE가 사용되었지만, 분류모델의 손실함수는 Cross Entropy이기 때문
MSE의 경우 예측값과 실제값 사이의 거리차를 제곱하지만, Cross Entropy의 경우 두 값의 차이가 클수록
기하급수적으로 손실이 늘어나는 차이가 존재한다.
'구글 머신러닝 스터디잼(중급) > Launching into Machine Learning' 카테고리의 다른 글
| ML History 3 : Neural Networks (0) | 2019.10.20 |
|---|---|
| ML History 2 : Perceptron (0) | 2019.10.18 |
| ML History 1 : Linear Regression (0) | 2019.10.18 |
| Supervised Learning 1 :Supervised Learning (0) | 2019.10.15 |
| Introduction to Launching into ML (0) | 2019.10.15 |